
iOS 开发中总会用到各种缓存,最初我是用的一些开源的缓存库,但到总觉得缺少某些功能,或某些 API 设计的不够好用。YYCache (https://github.com/ibireme/YYCache) 是我新造的一个轮子,下面说一下这个轮子的设计思路。
内存缓存
通常一个缓存是由内存缓存和磁盘缓存组成,内存缓存提供容量小但高速的存取功能,磁盘缓存提供大容量但低速的持久化存储。相对于磁盘缓存来说,内存缓存的设计要更简单些,下面是我调查的一些常见的内存缓存。
NSCache 是苹果提供的一个简单的内存缓存,它有着和 NSDictionary 类似的 API,不同点是它是线程安全的,并且不会 retain key。我在测试时发现了它的几个特点:NSCache 底层并没有用 NSDictionary 等已有的类,而是直接调用了 libcache.dylib,其中线程安全是由 pthread_mutex 完成的。另外,它的性能和 key 的相似度有关,如果有大量相似的 key (比如 “1”, “2”, “3”, …),NSCache 的存取性能会下降得非常厉害,大量的时间被消耗在 CFStringEqual() 上,不知这是不是 NSCache 本身设计的缺陷。
TMMemoryCache 是 TMCache 的内存缓存实现,最初由 Tumblr 开发,但现在已经不再维护了。TMMemoryCache 实现有很多 NSCache 并没有提供的功能,比如数量限制、总容量限制、存活时间限制、内存警告或应用退到后台时清空缓存等。TMMemoryCache 在设计时,主要目标是线程安全,它把所有读写操作都放到了同一个 concurrent queue 中,然后用 dispatch_barrier_async 来保证任务能顺序执行。它错误的用了大量异步 block 回调来实现存取功能,以至于产生了很大的性能和死锁问题。
PINMemoryCache 是 Tumblr 宣布不在维护 TMCache 后,由 Pinterest 维护和改进的一个内存缓存。它的功能和接口基本和 TMMemoryCache 一样,但修复了性能和死锁的问题。它同样也用 dispatch_semaphore 来保证线程安全,但去掉了dispatch_barrier_async,避免了线程切换带来的巨大开销,也避免了可能的死锁。
YYMemoryCache 是我开发的一个内存缓存,相对于 PINMemoryCache 来说,我去掉了异步访问的接口,尽量优化了同步访问的性能,用 OSSpinLock 来保证线程安全。另外,缓存内部用双向链表和 NSDictionary 实现了 LRU 淘汰算法,相对于上面几个算是一点进步吧。
下面的单线程的 Memory Cache 性能基准测试:
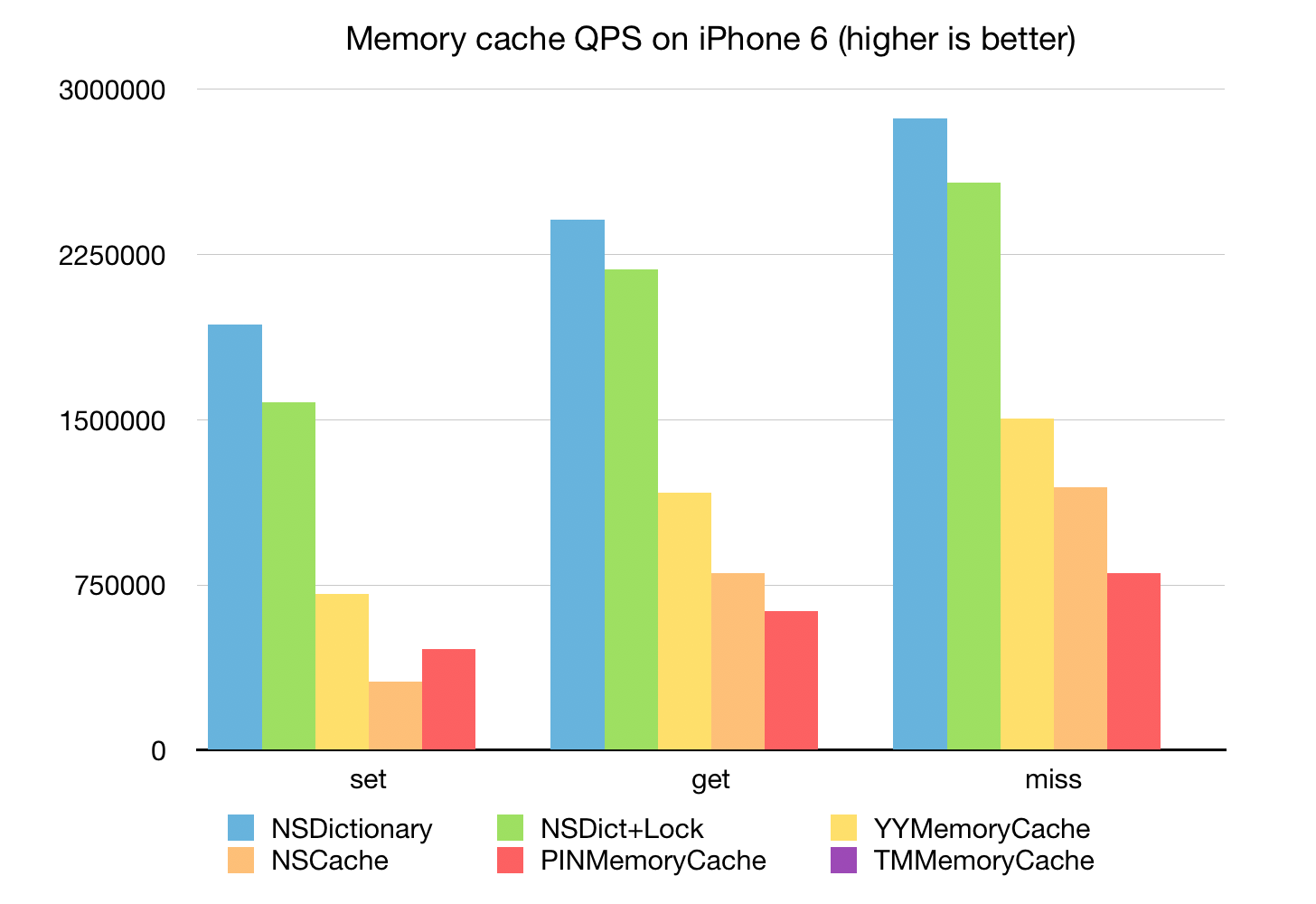
可以看到 YYMemoryCache 的性能不错,仅次于 NSDictionary + OSSpinLock;
NSCache 的写入性能稍差,读取性能不错;
PINMemoryCache 的读写性能也还可以,但读取速度差于 NSCache;
TMMemoryCache 性能太差以至于图上都看不出来了。
磁盘缓存
为了设计一个比较好的磁盘缓存,我调查了大量的开源库,包括 TMDiskCache、PINDiskCache、SDWebImage、FastImageCache 等,也调查了一些闭源的实现,包括 NSURLCache、Facebook 的 FBDiskCache 等。他们的实现技术大致分为三类:基于文件读写、基于 mmap 文件内存映射、基于数据库。
TMDiskCache, PINDiskCache, SDWebImage 等缓存,都是基于文件系统的,即一个 Value 对应一个文件,通过文件读写来缓存数据。他们的实现都比较简单,性能也都相近,缺点也是同样的:不方便扩展、没有元数据、难以实现较好的淘汰算法、数据统计缓慢。
FastImageCache 采用的是 mmap 将文件映射到内存。用过 MongoDB 的人应该很熟悉 mmap 的缺陷:热数据的文件不要超过物理内存大小,不然 mmap 会导致内存交换严重降低性能;另外内存中的数据是定时 flush 到文件的,如果数据还未同步时程序挂掉,就会导致数据错误。抛开这些缺陷来说,mmap 性能非常高。
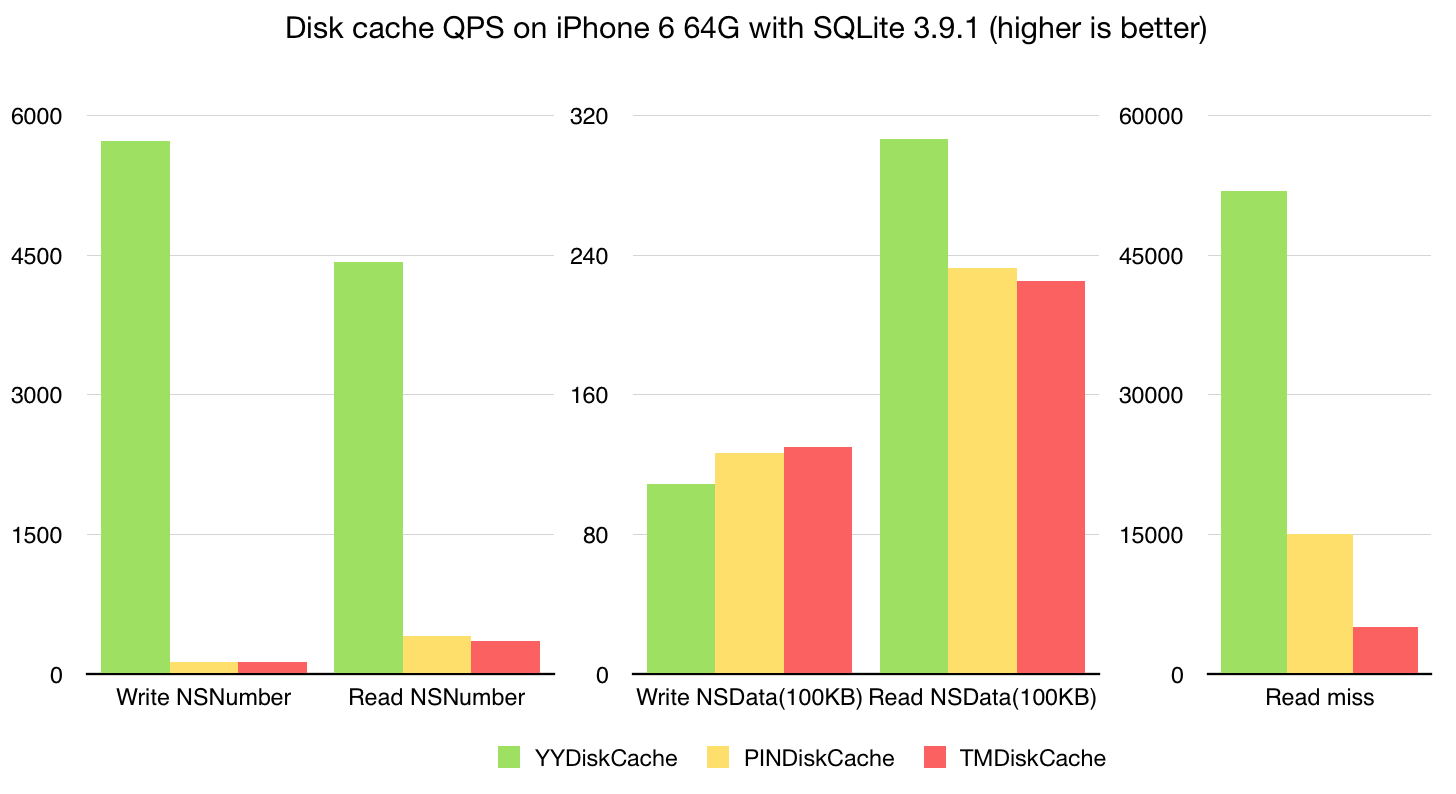
NSURLCache、FBDiskCache 都是基于 SQLite 数据库的。基于数据库的缓存可以很好的支持元数据、扩展方便、数据统计速度快,也很容易实现 LRU 或其他淘汰算法,唯一不确定的就是数据库读写的性能,为此我评测了一下 SQLite 在真机上的表现。iPhone 6 64G 下,SQLite 写入性能比直接写文件要高,但读取性能取决于数据大小:当单条数据小于 20K 时,数据越小 SQLite 读取性能越高;单条数据大于 20K 时,直接写为文件速度会更快一些。这和 SQLite 官网的描述基本一致。另外,直接从官网下载最新的 SQLite 源码编译,会比 iOS 系统自带的 sqlite3.dylib 性能要高很多。基于 SQLite 的这种表现,磁盘缓存最好是把 SQLite 和文件存储结合起来:key-value 元数据保存在 SQLite 中,而 value 数据则根据大小不同选择 SQLite 或文件存储。NSURLCache 选定的数据大小的阈值是 16K;FBDiskCache 则把所有 value 数据都保存成了文件。
我的 YYDiskCache 也是采用的 SQLite 配合文件的存储方式,在 iPhone 6 64G 上的性能基准测试结果见下图。在存取小数据 (NSNumber) 时,YYDiskCache 的性能远远高出基于文件存储的库;而较大数据的存取性能则比较接近了。但得益于 SQLite 存储的元数据,YYDiskCache 实现了 LRU 淘汰算法、更快的数据统计,更多的容量控制选项。
备注:
关于锁:
OSSpinLock 自旋锁,性能最高的锁。原理很简单,就是一直 do while 忙等。它的缺点是当等待时会消耗大量 CPU 资源,所以它不适用于较长时间的任务。对于内存缓存的存取来说,它非常合适。
dispatch_semaphore 是信号量,但当信号总量设为 1 时也可以当作锁来。在没有等待情况出现时,它的性能比 pthread_mutex 还要高,但一旦有等待情况出现时,性能就会下降许多。相对于 OSSpinLock 来说,它的优势在于等待时不会消耗 CPU 资源。对磁盘缓存来说,它比较合适。
关于 Realm:
Realm 是一个比较新的数据库,针对移动应用所设计。它的 API 对于开发者来说非常友好,比 SQLite、CoreData 要易用很多,但相对的坑也有不少。我在测试 SQLite 性能时,也尝试对它做了些简单的评测。我从 Realm 官网下载了它提供的 benchmark 项目,更新 SQLite 到官网最新的版本,并启用了 SQLite 的 sqlite3_stmt 缓存。我的评测结果显示 Realm 在写入性能上差于 SQLite,读取小数据时也差 SQLite 不少,读取较大数据时 Realm 有很大的优势。当然这只是我个人的评测,可能并不能反映真实项目中具体的使用情况。我想看看它的实现原理,但发现 Realm 的核心 realm-core 是闭源的(评论里 Realm 员工提到目前有在 Apache 2.0 授权下的开源计划),能知道的是 Realm 应该用 了 mmap 把文件映射到内存,所以才在较大数据读取时获得很高的性能。另外我注意到添加了 Realm 的 App 会在启动时向某几个 IP 发送数据,评论中有 Realm 员工反馈这是发送匿名统计数据,并且只针对模拟器和 Debug 模式。这部分代码目前是开源的,并且可以通过环境变量 REALM_DISABLE_ANALYTICS 来关闭,如果有使用 Realm 的可以注意一下。
厉害!!!
Realm 官网号称不是比 SQLite 快么,静默发数据,还有这黑幕啊。。
大赞~
犀利
90后大牛
学习了! :roll:
您好,我是Realm的beeender。
有关您文章中提到的“另外我注意到添加了 Realm 的 App 会在启动时向某几个 IP 发送数据”是不准确的。Realm为了改进产品,的确在收集匿名数据。但收集动作只会在用户运行模拟器,或者加载debugger时进行。收集行为绝对不会在生产版本或者在您用户的设备上运行时发生。这些可以在我们的文档中查看 https://realm.io/docs/swift/latest/#i-see-a-network-call-to-mixpanel-when-i-run-my-app-what-is-that 并且,这部分的代码都是开源的,您可以随时通过环境变量 REALM_DISABLE_ANALYTICS 来关闭它。
关于Realm底层引擎的收费和开源问题:Realm核心引擎还需要些代码清理工作,我们确实有在Apache 2.0授权下开源Realm底层引擎的计划。另外,个人暂时没有看出有迹象Realm会在未来收费 ;-)
多谢您的意见,如果您还有更多建议,非常欢迎您通过邮件来和我们探讨!
感谢回复,我会更新一下文章~ ;-)
不小心又到这个网页了,realm-core 已经开源小一年了 :twisted:
看你的代码感觉像一种享受,不得不佩服啊。
– (NSArray *)getItemForKeys:(NSArray *)keys {
if (keys.count == 0) return nil;
NSMutableArray *items = [self _dbGetItemWithKeys:keys excludeInlineData:NO];
if (_type != YYKVStorageTypeSQLite) {
for (NSInteger i = 0, max = items.count; i 0) {
[self _dbUpdateAccessTimeWithKeys:keys];
}
return items.count ? items : nil;
}
这段代码,在循环的过程中又做删除操作,你确定这样没问题吗? (删到后面不会数组越界?)
这段代码你漏看了两行:https://github.com/ibireme/YYCache/blob/master/YYCache/YYKVStorage.m#L993-L994
嗯,是的,受教了 :|
麻烦问下你是怎么进行性能测试并生成这些图表的?
测试代码见 Github,图是用 Numbers 或者 Keynote 画的。
佩服 :grin:
– (void)_trimInBackground {
__weak typeof(self) _self = self;
dispatch_async(_queue, ^{
__strong typeof(_self) self = _self;
if (!self) return;
dispatch_semaphore_wait(self->_lock, DISPATCH_TIME_FOREVER);
// [self _trimToCost:self.countLimit]; 错误
[self _trimToCost:self.costLimit];
[self _trimToCount:self.countLimit];
[self _trimToAge:self.ageLimit];
[self _trimToFreeDiskSpace:self.freeDiskSpaceLimit];
dispatch_semaphore_signal(self->_lock);
});
}
不知道我做注释的地方是不是楼主笔误 还是我理解的有问题。
应该是 bug 吧,感谢提出。话说这种问题提到 Github Issues 里更好些,那样容易跟踪和获得反馈~
佩服。向你学习。。。
“TMMemoryCache 在设计时,主要目标是线程安全,它把所有读写操作都放到了同一个 serial queue 中,然后用 dispatch_semaphore 来保证最多只有一个线程访问 queue。”感觉这句话有点问题呢,TMMemoryCache中的semaphore是为了阻塞调用线程,因为它在同步方法中其实是调用的异步读取方法,semaphore阻塞线程知道读取完成,然后方法返回。这样做也无法保证最多只有一个线程访问queue。不知道我的理解有没有问题,请大神赐教
感谢指正 ;-) 我又看了下 TMMemoryCache,它用的是 dispatch_barrier_async。。。我更新了下文章。
点赞。
太棒了,我也喜欢这样研究性能问题,看起来感觉很舒服。 特别是知道什么方法消耗高,哪个消耗低。感觉很好
请问有没有具体的列表,具体说哪些方法是比较耗性能的,这样的东西,希望可以学习学习
_YYLinkedMapNode *node = [_lru removeTailNode];
if (_lru->_releaseAsynchronously) {
dispatch_queue_t queue = _lru->_releaseOnMainThread ? dispatch_get_main_queue() : YYMemoryCacheGetReleaseQueue();
dispatch_async(queue, ^{
[node class]; //hold and release in queue
});
} else if (_lru->_releaseOnMainThread && !pthread_main_np()) {
dispatch_async(dispatch_get_main_queue(), ^{
[node class]; //hold and release in queue
});
}
[node class]; 这种在queue上调用对象的方法,能保证node是在这个queue上release掉,这个确定么?想想是的但是总觉得不是很确定
你可以给 node 加个 dealloc 下断点看看。
评论 :oops: 赞
应该是node在执行完这个方法后就出了作用域了,reference会减1,但是此时node不会被dealloc,因为block 中retain了node,使得node的reference count为1,当执完block后,node的reference count又-1,此时node就会在block对应的queue上release了。的确很巧妙
Cache设计使用LRU,插入和替换的复杂度是O(1),但是查找的复杂度是O(n),为了让查找效率也达到O(1),是否已经使用了类似 hash table的补充算法?
此处 LRU 是用双向链表配合 NSDictionary 实现的,增、删、改、查、清空的时间复杂度都是 O(1),这个在头文件注释里也有说明。
你好,我把你的源码研究了下,有个地方不是很理解,就是memory超过了limit,removeTail就可以了,为什么你每个都加了
if (holder.count) {
dispatch_queue_t queue = _lru->_releaseOnMainThread ? dispatch_get_main_queue() : YYMemoryCacheGetReleaseQueue();
dispatch_async(queue, ^{
[holder count]; // release in queue
});
}
这个代码,为什么要求下count呢?
holder 持有了待释放的对象,这些对象应该根据配置在不同线程进行释放(release)。此处 holder 被 block 持有,然后在另外的 queue 中释放。[holder count] 只是为了让 holder 被 block 捕获,保证编译器不会优化掉这个操作,所以随便调用了一个方法。
node继承nsobject,也是oc对象,removeTailNode之后,node的计数应该为0了,不是会自动释放的嘛,为什么要加这个呢,还是不大理解
是为了在特定queue中释放
因为OC对象的释放也是比较性能的,我想博主的目的是把OC对象放到子线程中去release是出于对性能的考虑。这在博主的《iOS 保持界面流畅的技巧》(http://blog.ibireme.com/2015/11/12/smooth_user_interfaces_for_ios/)一文中也有所提到。感叹博主的设计技巧。手动崇拜!
评论 :twisted: 博主就是神一样的存在
调用 [holder count] 方法只是让主队列或者YYMemoryCacheGetReleaseQueue持有里边对象,并且在指定的队列中进行release
看代码YYMemoryCache中是用OSSpinLockLock控制同步的,但是在YYDiskCache里面还是用的dispatch_semaphore_wait,为什么没在YYDiskCache里面也是用OSSpinLockLock?是有什么其他理由吗?
DiskCache 锁占用时间可能会比较长,如果用 SpinLock 会在锁存在竞争时占用大量 CPU 资源。
yy你好,看到你说 dispatch_semaphore 在没有等待的情况下比 pthread_mutex 的效率高,我模拟了一个循环的上锁和解锁的过程,下面是代码,但是我得出的结果是 semaphore 使用的时间比 pthread_mutex 更多,是我的测试有问题吗?求指教
var then = 0.0
var now = 0.0
let CYCLEINDEX = 1024 * 1024 * 64
func semaphore_Test() {
let semaphore = dispatch_semaphore_create(1)
then = CFAbsoluteTimeGetCurrent()
for _ in 0 ..< CYCLEINDEX {
dispatch_semaphore_wait(semaphore, DISPATCH_TIME_FOREVER)
dispatch_semaphore_signal(semaphore)
}
now = CFAbsoluteTimeGetCurrent()
print("semaphore:\(now – then)")
}
func pthread_mutex_Test() {
var mutex = pthread_mutex_t()
then = CFAbsoluteTimeGetCurrent()
for _ in 0 ..< CYCLEINDEX {
pthread_mutex_lock(&mutex)
pthread_mutex_unlock(&mutex)
}
now = CFAbsoluteTimeGetCurrent()
print("pthread_mutex:\(now – then)")
}
// semaphore:7.91026800870895
// pthread_mutex:1.36437898874283
貌似代码出现了乱码???。。。其实就是一个循环,进行上锁和解锁的过程,但是 semaphore使用的时间比 pthread_mutex 多很多
用 C 来写,用 Release 模式编译,在真机上跑。
有没有测试在多个线程中取数据的效率,还没仔细看代码和文章,先问一下
多线程下,QPS 不会高于单线程,但会降低多少要看具体情况。由于 cache 内部是用锁来保证线程安全的,所以线程数越多、访问竞争越激烈、CPU 资源就消耗越大,QPS 也就越低。在 App 开发里,一般使用时倒不会遇到这种极端情况。
– (void)_trimInBackground {
dispatch_async(_queue, ^{
[self _trimToCost:self->_costLimit];
[self _trimToCount:self->_countLimit];
[self _trimToAge:self->_ageLimit];
});
}
问个小白问题,_queue是串行队列,那为什么在_trimToCost中还要加上自旋锁呀?难道不应该是线程安全的吗?
lock 是为了保证内部数据的线程安全,所有访问接口都要经过这个 lock。_queue 只是用来执行后台检查和移除的逻辑,它内部还是要用 lock 来锁住数据的。
楼主你好,我想针对TM和PIN提一个问题,我查看了一下两者的源码之后发现,TM是在在读写磁盘缓存的时候使用了同步队列,在PIN中虽然改成了并行队列,但是依然会通过semaphore去保证同时只有一个任务在执行,感觉和串行队列没什么区别,两者性能差距为什么会这么大呢?
TMCache 里面,同步访问的逻辑,内部是把操作放到其他线程去执行,等待其完成后再回到当前线程,这就会让同步访问的方法内部产生线程切换等很重的操作,性能就会非常差。PINCache 里,同步访问就是简单 lock 一下,这性能就没问题了。
Hi,yy 我看了你的代码有一点不明白想询问你一下
while (!finish) {
if (OSSpinLockTry(&_lock)) {
if (_lru->_totalCount > countLimit) {
_YYLinkedMapNode *node = [_lru removeTailNode];
if (node) [holder addObject:node];
} else {
finish = YES;
}
OSSpinLockUnlock(&_lock);
} else {
usleep(10 * 1000); //10 ms
}
}
这里用OSSpinLockTry,当当前自旋锁无法获取时直接让线程sleep 10 ms,我想问一下这边为什么不用OSSpinLockLock而是直接让线程sleep一下呢?不太明白求解,谢谢
为了尽量保证所有对外的访问方法都不至于阻塞,这个对象移除的方法应当尽量避免与其他访问线程产生冲突。当然这只能在很少一部分使用场景下才可能有些作用吧,而且作用可能也不明显。。。 :?:
if (_lru->_releaseAsynchronously) {
dispatch_queue_t queue = _lru->_releaseOnMainThread ? dispatch_get_main_queue() : YYMemoryCacheGetReleaseQueue();
dispatch_async(queue, ^{
[node class]; //hold and release in queue
});
}
这句代码为什么要调用一次 [node class] 呢
这个应该是随便调的一个方法都可以,让它在特定的queue里释放
项目中使用到YYWebImage读取网络图片,却出现图像混乱,单步调试过程中发现,用正确的URL拿到的却是其他的图片,目前正在看缓存机制,想问楼主,是不是在写缓存时候,产生的,该如何解决?
有问题可以在 Github 新建 Issue,方便交流和跟进。
“TMMemoryCache 在设计时,主要目标是线程安全,它把所有读写操作都放到了同一个 concurrent queue 中,然后用 dispatch_barrier_async 来保证任务能顺序执行。”
barrier准确的说应该是保证被包裹的代码块在并发队列中执行时的独占性,就如同跑在串行队列中一样,不知道这样说对不对。
还有想请教一点:它错误的用了大量异步 block 回调来实现存取功能,以至于产生了很大的性能和死锁问题,这个能否多解释一下?
这里的解释会更详细一些:https://engineering.pinterest.com/blog/open-sourcing-pincache
看了PinCache 的源码明白了,PinMemoryCache 同步读的时候,是真正的同步读,并且用信号量控制了同步读在并发队列的并行量;而 TMMemCache的同步读,其实是用信号量将异步变成了同步,但是会存在并发队列忙碌时,无法执行回调发信号造成死锁。
同为90后,这差距真是让人汗颜啊!考究精神值得学习
SQLite官网没有找到iOS版本的下载,有Doc,Android和WinPhone版。
最近也在研究缓存, 主要用在主题Color,图片等方面,避免反复GPU创建。
同发现NSCache性能略弱, 但是如何用NSDictionary + Lock, 对其它的开销也不小,
所以综合考虑还是用NSCache吧
请教一下YY,YYDiskCache和Realm/CoreData这些相比,一个是磁盘缓存,一个是数据库,他们到底有什么区别?一直没法清晰的区分,还请不吝赐教~
您好,我想问一下怎么样测试程序的效率?(您上面的图表用上面软件测试出来的?)
您好,能否说一下为什么TMMemoryCache 的concurrent queue + dispatch_barrier_async + 异步block 的设计会导致性能问题和死锁?如果换用同步block是不是就没事了?
主要是因为信号量那个吧? :smile:
博主神一般的存在着 :roll:
:cool: 学到很多知识哦,每当没事做的时候看看大神的博客,瞬间又有动力了,?
“TMMemoryCache错误的用了大量异步 block 回调来实现存取功能,以至于产生了很大的性能和死锁问题。”
性能问题是由于线程切换的消耗吗?死锁的话代码里哪些用法是不安全的?
请教个问题,YYMemoryCache里双向链表存在的作用是什么?主要作用是用来trimToCost/ToCount/ToAge?
实现 LRU 算法,细节在 _YYLinkedMap 里。
“NSCache 是苹果提供的一个简单的内存缓存,它有着和 NSDictionary 类似的 API,不同点是它是线程安全的,并且不会 retain key。”
retain key,应该是笔误,是不会copy key.
缓存 怎么清楚呢!我在项目中集成了 YYDiskCache, APP 占用的存储空间不断增大,尝试调用 yycache 的removeAllObjects方法 和手动删除 缓存路径下的文件,在系统设置里 App占用的存储空间减少的不是很明显!
:roll: 大赞。。不过有个小疑问想请教下。。。为什么要在特定的queue释放对象,这是有什么考量吗。。。。求答复。。。
参考博主的《iOS 保持界面流畅的技巧》
你好,
我查看YYMemoryCache源码的时候,看到你在init的时候开了一个定时器去检测缓存大小、数量、缓存时间。我感觉定时器会消耗性能,这里可以在每次写或者取缓存的时候进行一次检测吗?
YYMemoryCache函数 每次传进去的cost都是0,这样设置costLimit还有啥意义
– (void)setObject:(id)object forKey:(id)key {
[self setObject:object forKey:key withCost:0];
}
PINCache也有同样的问题
评论 :| NSCache 也是这样实现的
YYMemoryCache函数 每次传进去的cost都是0,这样设置costLimit还有啥意义,并没有实现内存LRU算法
– (void)setObject:(id)object forKey:(id)key {
[self setObject:object forKey:key withCost:0];
}
真心佩服 写出如此好的代码和文章
激励自己加油~
大神您好,能否添加个联系方式,有一些关于缓存方面的问题想向您请教一下。
很好
很讲究,可是并没有太大的改善,encode decode 仍然需要很大的代码量。此外不支持Swit呀,一个项目如果model不是Swift的,其他的很多地方就很难是Swift的了,这个阻碍了想Swift的迁移。一般场景下有内存缓存足够快了,disk慢让它排队慢慢后台去写好了。
NSFileManager + SQLite, 取长避短,只能说聪明,但并没有突破
你好:
读取速度的比较界限,好像是100kb,我自己测试和官网给出的好像都是100kb
前辈你好,如你文中所说:NSCache 是苹果提供的一个简单的内存缓存,它有着和 NSDictionary 类似的 API,不同点是它是线程安全的,并且不会 retain key。
其实NSDictionary是不会 retain key的,而NSCache才会retain key,这个我在GNU的objc实现中关于NSCache里有看到下面一段:
newObject->object = RETAIN(obj);
newObject->key = RETAIN(key);
newObject->cost = num;
虽然不能代表苹果自己,但是经过我手动测试,的确是会对key进行一次retain + 1。而NSDictionary只是有可能对key进行copy(在key不可变时不copy)。?
你好,我发现Storage里面即使是YYKVStorageTypeFile类型的Cache也会把数据存到Sqlite一份。既然如此为什么还要存一份到磁盘里,数据的操作都用Sqlite不好吗
同样不理解
为什么一份数据 通过yykvstoragetypefile类型存储的时候 除了存文件 还要存sqlite。
这不是变相占用空间了吗
if (fileName.length == 0) {
sqlite3_bind_blob(stmt, 4, value.bytes, (int)value.length, 0);
} else {
sqlite3_bind_blob(stmt, 4, NULL, 0, 0);
}
存在磁盘中的文件
是sqlite存储value的详情
sqlite中存储的只是类似文件的索引信息
偶像 问你个问题啊 一定要回答我啊 __unsafe_unretained _YYLinkedMapNode *_prev; // retained by dic
这个地方 我把前面的 __unsafe_unretained 换成__weak 是不是又可以的,大家又看到我这个评论的也回复一下 讨论一下呗
可以是可以,但是可以参考作者另一篇文章:https://blog.ibireme.com/2015/10/23/ios_model_framework_benchmark/ 。文末 YYModel 性能优化的几个 Tip 中第5条
“5. 避免多余的内存管理方法
在 ARC 条件下,默认声明的对象是 __strong 类型的,赋值时有可能会产生 retain/release 调用,如果一个变量在其生命周期内不会被释放,则使用 __unsafe_unretained 会节省很大的开销。
访问具有 __weak 属性的变量时,实际上会调用 objc_loadWeak() 和 objc_storeWeak() 来完成,这也会带来很大的开销,所以要避免使用 __weak 属性。
创建和使用对象时,要尽量避免对象进入 autoreleasepool,以避免额外的资源开销。”
另外内存中的数据是定时 flush 到文件的,如果数据还未同步时程序挂掉,就会导致数据错误。 请问这句话是怎样证明的?我印象中内存映射文件会在进程退出时由系统将内存中的数据同步回文件的。