这篇文章会非常详细的分析 iOS 界面构建中的各种性能问题以及对应的解决思路,同时给出一个开源的微博列表实现,通过实际的代码展示如何构建流畅的交互。
Index
演示项目
屏幕显示图像的原理
卡顿产生的原因和解决方案
CPU 资源消耗原因和解决方案
GPU 资源消耗原因和解决方案
AsyncDisplayKit
ASDK 的由来
ASDK 的资料
ASDK 的基本原理
ASDK 的图层预合成
ASDK 异步并发操作
Runloop 任务分发
微博 Demo 性能优化技巧
预排版
预渲染
异步绘制
全局并发控制
更高效的异步图片加载
其他可以改进的地方
如何评测界面的流畅度
演示项目
在开始技术讨论前,你可以先下载我写的 Demo 跑到真机上体验一下:https://github.com/ibireme/YYKit。 Demo 里包含一个微博的 Feed 列表、发布视图,还包含一个 Twitter 的 Feed 列表。为了公平起见,所有界面和交互我都从官方应用原封不动的抄了过来,数据也都是从官方应用抓取的。你也可以自己抓取数据替换掉 Demo 中的数据,方便进行对比。尽管官方应用背后的功能更多更为复杂,但不至于会带来太大的交互性能差异。
这个 Demo 最低可以运行在 iOS 6 上,所以你可以把它跑到老设备上体验一下。在我的测试中,即使在 iPhone 4S 或者 iPad 3 上,Demo 列表在快速滑动时仍然能保持 50~60 FPS 的流畅交互,而其他诸如微博、朋友圈等应用的列表视图在滑动时已经有很严重的卡顿了。
微博的 Demo 有大约四千行代码,Twitter 的只有两千行左右代码,第三方库只用到了 YYKit,文件数量比较少,方便查看。好了,下面是正文。
屏幕显示图像的原理
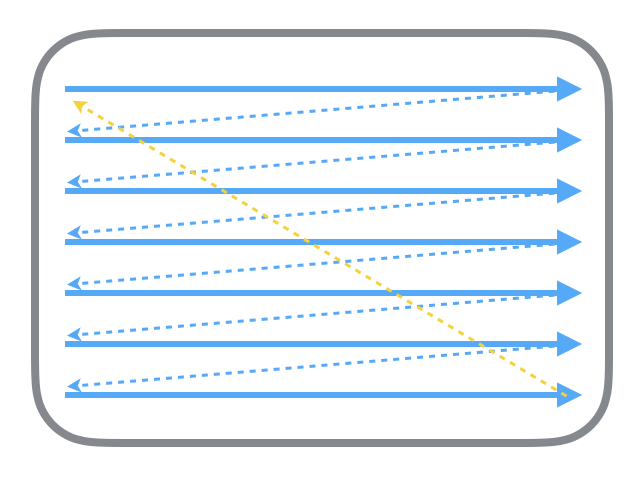
首先从过去的 CRT 显示器原理说起。CRT 的电子枪按照上面方式,从上到下一行行扫描,扫描完成后显示器就呈现一帧画面,随后电子枪回到初始位置继续下一次扫描。为了把显示器的显示过程和系统的视频控制器进行同步,显示器(或者其他硬件)会用硬件时钟产生一系列的定时信号。当电子枪换到新的一行,准备进行扫描时,显示器会发出一个水平同步信号(horizonal synchronization),简称 HSync;而当一帧画面绘制完成后,电子枪回复到原位,准备画下一帧前,显示器会发出一个垂直同步信号(vertical synchronization),简称 VSync。显示器通常以固定频率进行刷新,这个刷新率就是 VSync 信号产生的频率。尽管现在的设备大都是液晶显示屏了,但原理仍然没有变。
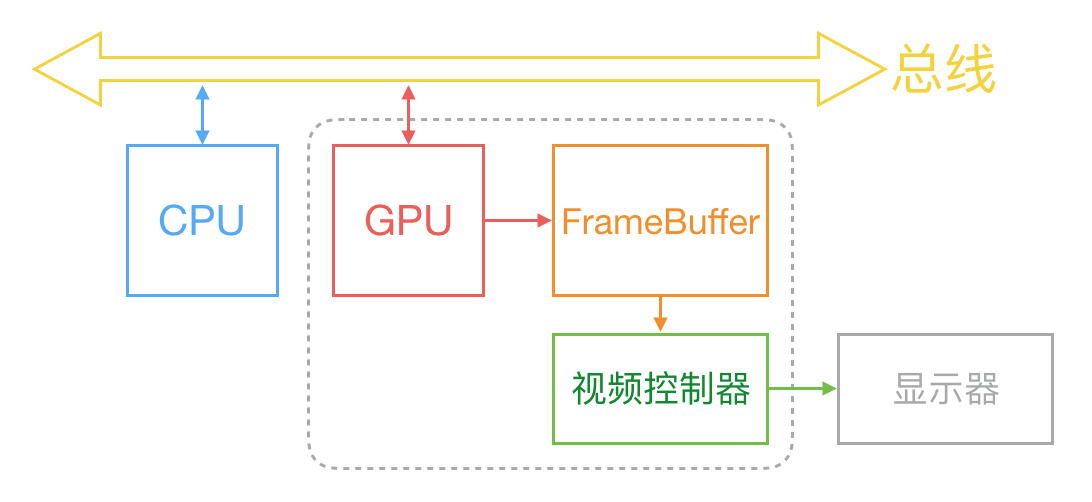
通常来说,计算机系统中 CPU、GPU、显示器是以上面这种方式协同工作的。CPU 计算好显示内容提交到 GPU,GPU 渲染完成后将渲染结果放入帧缓冲区,随后视频控制器会按照 VSync 信号逐行读取帧缓冲区的数据,经过可能的数模转换传递给显示器显示。
在最简单的情况下,帧缓冲区只有一个,这时帧缓冲区的读取和刷新都都会有比较大的效率问题。为了解决效率问题,显示系统通常会引入两个缓冲区,即双缓冲机制。在这种情况下,GPU 会预先渲染好一帧放入一个缓冲区内,让视频控制器读取,当下一帧渲染好后,GPU 会直接把视频控制器的指针指向第二个缓冲器。如此一来效率会有很大的提升。
双缓冲虽然能解决效率问题,但会引入一个新的问题。当视频控制器还未读取完成时,即屏幕内容刚显示一半时,GPU 将新的一帧内容提交到帧缓冲区并把两个缓冲区进行交换后,视频控制器就会把新的一帧数据的下半段显示到屏幕上,造成画面撕裂现象,如下图:

为了解决这个问题,GPU 通常有一个机制叫做垂直同步(简写也是 V-Sync),当开启垂直同步后,GPU 会等待显示器的 VSync 信号发出后,才进行新的一帧渲染和缓冲区更新。这样能解决画面撕裂现象,也增加了画面流畅度,但需要消费更多的计算资源,也会带来部分延迟。
那么目前主流的移动设备是什么情况呢?从网上查到的资料可以知道,iOS 设备会始终使用双缓存,并开启垂直同步。而安卓设备直到 4.1 版本,Google 才开始引入这种机制,目前安卓系统是三缓存+垂直同步。
卡顿产生的原因和解决方案
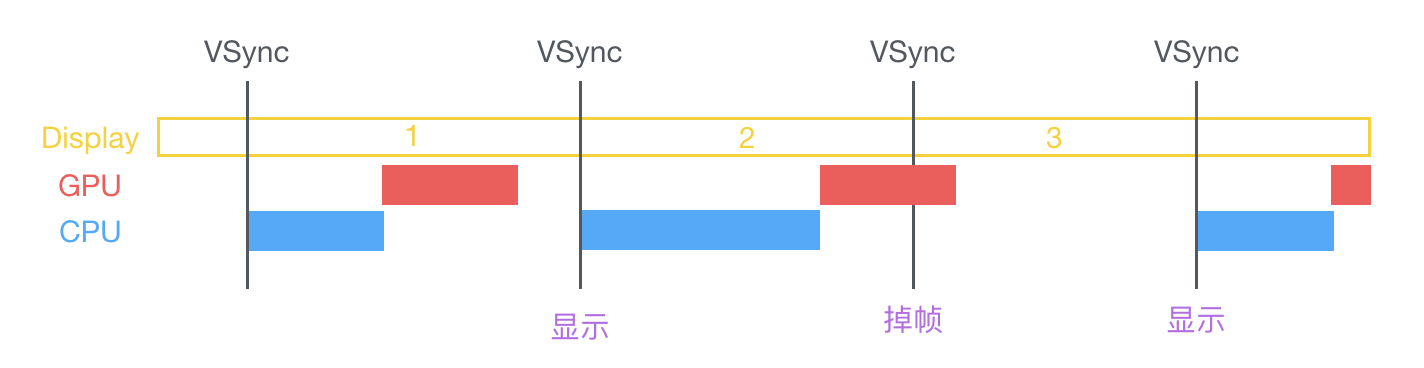
在 VSync 信号到来后,系统图形服务会通过 CADisplayLink 等机制通知 App,App 主线程开始在 CPU 中计算显示内容,比如视图的创建、布局计算、图片解码、文本绘制等。随后 CPU 会将计算好的内容提交到 GPU 去,由 GPU 进行变换、合成、渲染。随后 GPU 会把渲染结果提交到帧缓冲区去,等待下一次 VSync 信号到来时显示到屏幕上。由于垂直同步的机制,如果在一个 VSync 时间内,CPU 或者 GPU 没有完成内容提交,则那一帧就会被丢弃,等待下一次机会再显示,而这时显示屏会保留之前的内容不变。这就是界面卡顿的原因。
从上面的图中可以看到,CPU 和 GPU 不论哪个阻碍了显示流程,都会造成掉帧现象。所以开发时,也需要分别对 CPU 和 GPU 压力进行评估和优化。
CPU 资源消耗原因和解决方案
对象创建
对象的创建会分配内存、调整属性、甚至还有读取文件等操作,比较消耗 CPU 资源。尽量用轻量的对象代替重量的对象,可以对性能有所优化。比如 CALayer 比 UIView 要轻量许多,那么不需要响应触摸事件的控件,用 CALayer 显示会更加合适。如果对象不涉及 UI 操作,则尽量放到后台线程去创建,但可惜的是包含有 CALayer 的控件,都只能在主线程创建和操作。通过 Storyboard 创建视图对象时,其资源消耗会比直接通过代码创建对象要大非常多,在性能敏感的界面里,Storyboard 并不是一个好的技术选择。
尽量推迟对象创建的时间,并把对象的创建分散到多个任务中去。尽管这实现起来比较麻烦,并且带来的优势并不多,但如果有能力做,还是要尽量尝试一下。如果对象可以复用,并且复用的代价比释放、创建新对象要小,那么这类对象应当尽量放到一个缓存池里复用。
对象调整
对象的调整也经常是消耗 CPU 资源的地方。这里特别说一下 CALayer:CALayer 内部并没有属性,当调用属性方法时,它内部是通过运行时 resolveInstanceMethod 为对象临时添加一个方法,并把对应属性值保存到内部的一个 Dictionary 里,同时还会通知 delegate、创建动画等等,非常消耗资源。UIView 的关于显示相关的属性(比如 frame/bounds/transform)等实际上都是 CALayer 属性映射来的,所以对 UIView 的这些属性进行调整时,消耗的资源要远大于一般的属性。对此你在应用中,应该尽量减少不必要的属性修改。
当视图层次调整时,UIView、CALayer 之间会出现很多方法调用与通知,所以在优化性能时,应该尽量避免调整视图层次、添加和移除视图。
对象销毁
对象的销毁虽然消耗资源不多,但累积起来也是不容忽视的。通常当容器类持有大量对象时,其销毁时的资源消耗就非常明显。同样的,如果对象可以放到后台线程去释放,那就挪到后台线程去。这里有个小 Tip:把对象捕获到 block 中,然后扔到后台队列去随便发送个消息以避免编译器警告,就可以让对象在后台线程销毁了。
|
1 2 3 4 5 |
NSArray *tmp = self.array; self.array = nil; dispatch_async(queue, ^{ [tmp class]; }); |
布局计算
视图布局的计算是 App 中最为常见的消耗 CPU 资源的地方。如果能在后台线程提前计算好视图布局、并且对视图布局进行缓存,那么这个地方基本就不会产生性能问题了。
不论通过何种技术对视图进行布局,其最终都会落到对 UIView.frame/bounds/center 等属性的调整上。上面也说过,对这些属性的调整非常消耗资源,所以尽量提前计算好布局,在需要时一次性调整好对应属性,而不要多次、频繁的计算和调整这些属性。
Autolayout
Autolayout 是苹果本身提倡的技术,在大部分情况下也能很好的提升开发效率,但是 Autolayout 对于复杂视图来说常常会产生严重的性能问题。随着视图数量的增长,Autolayout 带来的 CPU 消耗会呈指数级上升。具体数据可以看这个文章:http://pilky.me/36/。 如果你不想手动调整 frame 等属性,你可以用一些工具方法替代(比如常见的 left/right/top/bottom/width/height 快捷属性),或者使用 ComponentKit、AsyncDisplayKit 等框架。
文本计算
如果一个界面中包含大量文本(比如微博微信朋友圈等),文本的宽高计算会占用很大一部分资源,并且不可避免。如果你对文本显示没有特殊要求,可以参考下 UILabel 内部的实现方式:用 [NSAttributedString boundingRectWithSize:options:context:] 来计算文本宽高,用 -[NSAttributedString drawWithRect:options:context:] 来绘制文本。尽管这两个方法性能不错,但仍旧需要放到后台线程进行以避免阻塞主线程。
如果你用 CoreText 绘制文本,那就可以先生成 CoreText 排版对象,然后自己计算了,并且 CoreText 对象还能保留以供稍后绘制使用。
文本渲染
屏幕上能看到的所有文本内容控件,包括 UIWebView,在底层都是通过 CoreText 排版、绘制为 Bitmap 显示的。常见的文本控件 (UILabel、UITextView 等),其排版和绘制都是在主线程进行的,当显示大量文本时,CPU 的压力会非常大。对此解决方案只有一个,那就是自定义文本控件,用 TextKit 或最底层的 CoreText 对文本异步绘制。尽管这实现起来非常麻烦,但其带来的优势也非常大,CoreText 对象创建好后,能直接获取文本的宽高等信息,避免了多次计算(调整 UILabel 大小时算一遍、UILabel 绘制时内部再算一遍);CoreText 对象占用内存较少,可以缓存下来以备稍后多次渲染。
图片的解码
当你用 UIImage 或 CGImageSource 的那几个方法创建图片时,图片数据并不会立刻解码。图片设置到 UIImageView 或者 CALayer.contents 中去,并且 CALayer 被提交到 GPU 前,CGImage 中的数据才会得到解码。这一步是发生在主线程的,并且不可避免。如果想要绕开这个机制,常见的做法是在后台线程先把图片绘制到 CGBitmapContext 中,然后从 Bitmap 直接创建图片。目前常见的网络图片库都自带这个功能。
图像的绘制
图像的绘制通常是指用那些以 CG 开头的方法把图像绘制到画布中,然后从画布创建图片并显示这样一个过程。这个最常见的地方就是 [UIView drawRect:] 里面了。由于 CoreGraphic 方法通常都是线程安全的,所以图像的绘制可以很容易的放到后台线程进行。一个简单异步绘制的过程大致如下(实际情况会比这个复杂得多,但原理基本一致):
|
1 2 3 4 5 6 7 8 9 10 11 |
- (void)display { dispatch_async(backgroundQueue, ^{ CGContextRef ctx = CGBitmapContextCreate(...); // draw in context... CGImageRef img = CGBitmapContextCreateImage(ctx); CFRelease(ctx); dispatch_async(mainQueue, ^{ layer.contents = img; }); }); } |
GPU 资源消耗原因和解决方案
相对于 CPU 来说,GPU 能干的事情比较单一:接收提交的纹理(Texture)和顶点描述(三角形),应用变换(transform)、混合并渲染,然后输出到屏幕上。通常你所能看到的内容,主要也就是纹理(图片)和形状(三角模拟的矢量图形)两类。
纹理的渲染
所有的 Bitmap,包括图片、文本、栅格化的内容,最终都要由内存提交到显存,绑定为 GPU Texture。不论是提交到显存的过程,还是 GPU 调整和渲染 Texture 的过程,都要消耗不少 GPU 资源。当在较短时间显示大量图片时(比如 TableView 存在非常多的图片并且快速滑动时),CPU 占用率很低,GPU 占用非常高,界面仍然会掉帧。避免这种情况的方法只能是尽量减少在短时间内大量图片的显示,尽可能将多张图片合成为一张进行显示。
当图片过大,超过 GPU 的最大纹理尺寸时,图片需要先由 CPU 进行预处理,这对 CPU 和 GPU 都会带来额外的资源消耗。目前来说,iPhone 4S 以上机型,纹理尺寸上限都是 4096×4096,更详细的资料可以看这里:iosres.com。所以,尽量不要让图片和视图的大小超过这个值。
视图的混合 (Composing)
当多个视图(或者说 CALayer)重叠在一起显示时,GPU 会首先把他们混合到一起。如果视图结构过于复杂,混合的过程也会消耗很多 GPU 资源。为了减轻这种情况的 GPU 消耗,应用应当尽量减少视图数量和层次,并在不透明的视图里标明 opaque 属性以避免无用的 Alpha 通道合成。当然,这也可以用上面的方法,把多个视图预先渲染为一张图片来显示。
图形的生成。
CALayer 的 border、圆角、阴影、遮罩(mask),CASharpLayer 的矢量图形显示,通常会触发离屏渲染(offscreen rendering),而离屏渲染通常发生在 GPU 中。当一个列表视图中出现大量圆角的 CALayer,并且快速滑动时,可以观察到 GPU 资源已经占满,而 CPU 资源消耗很少。这时界面仍然能正常滑动,但平均帧数会降到很低。为了避免这种情况,可以尝试开启 CALayer.shouldRasterize 属性,但这会把原本离屏渲染的操作转嫁到 CPU 上去。对于只需要圆角的某些场合,也可以用一张已经绘制好的圆角图片覆盖到原本视图上面来模拟相同的视觉效果。最彻底的解决办法,就是把需要显示的图形在后台线程绘制为图片,避免使用圆角、阴影、遮罩等属性。
AsyncDisplayKit
AsyncDisplayKit 是 Facebook 开源的一个用于保持 iOS 界面流畅的库,我从中学到了很多东西,所以下面我会花较大的篇幅来对其进行介绍和分析。
ASDK 的由来

ASDK 的作者是 Scott Goodson (Linkedin),
他曾经在苹果工作,负责 iOS 的一些内置应用的开发,比如股票、计算器、地图、钟表、设置、Safari 等,当然他也参与了 UIKit framework 的开发。后来他加入 Facebook 后,负责 Paper 的开发,创建并开源了 AsyncDisplayKit。目前他在 Pinterest 和 Instagram 负责 iOS 开发和用户体验的提升等工作。

ASDK 自 2014 年 6 月开源,10 月发布 1.0 版。目前 ASDK 即将要发布 2.0 版。
V2.0 增加了更多布局相关的代码,ComponentKit 团队为此贡献很多。
现在 Github 的 master 分支上的版本是 V1.9.1,已经包含了 V2.0 的全部内容。
ASDK 的资料
想要了解 ASDK 的原理和细节,最好从下面几个视频开始:
2014.10.15 NSLondon – Scott Goodson – Behind AsyncDisplayKit
2015.03.02 MCE 2015 – Scott Goodson – Effortless Responsiveness with AsyncDisplayKit
2015.10.25 AsyncDisplayKit 2.0: Intelligent User Interfaces – NSSpain 2015
前两个视频内容大同小异,都是介绍 ASDK 的基本原理,附带介绍 POP 等其他项目。
后一个视频增加了 ASDK 2.0 的新特性的介绍。
除此之外,还可以到 Github Issues 里看一下 ASDK 相关的讨论,下面是几个比较重要的内容:
关于 Runloop Dispatch
关于 ComponentKit 和 ASDK 的区别
为什么不支持 Storyboard 和 Autolayout
如何评测界面的流畅度
之后,还可以到 Google Groups 来查看和讨论更多内容:
https://groups.google.com/forum/#!forum/asyncdisplaykit
ASDK 的基本原理
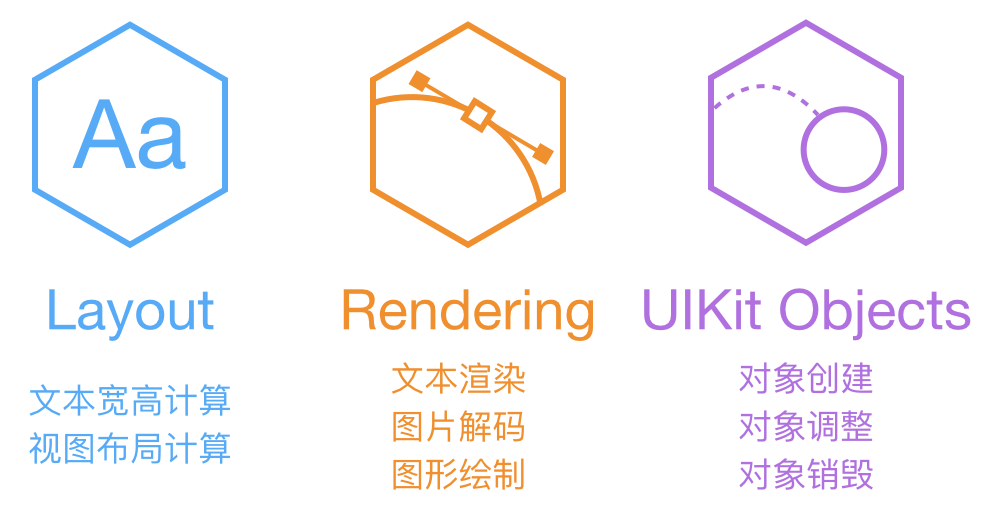
ASDK 认为,阻塞主线程的任务,主要分为上面这三大类。文本和布局的计算、渲染、解码、绘制都可以通过各种方式异步执行,但 UIKit 和 Core Animation 相关操作必需在主线程进行。ASDK 的目标,就是尽量把这些任务从主线程挪走,而挪不走的,就尽量优化性能。
为了达成这一目标,ASDK 尝试对 UIKit 组件进行封装:
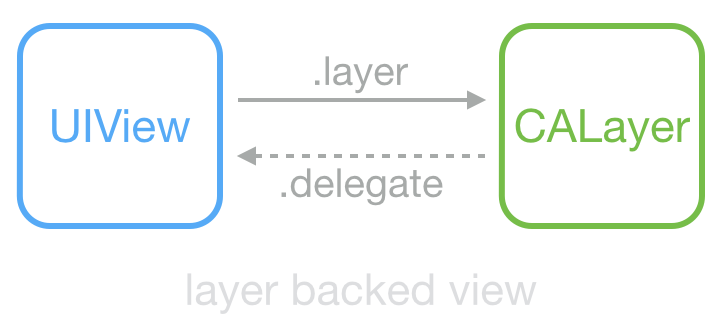
这是常见的 UIView 和 CALayer 的关系:View 持有 Layer 用于显示,View 中大部分显示属性实际是从 Layer 映射而来;Layer 的 delegate 在这里是 View,当其属性改变、动画产生时,View 能够得到通知。UIView 和 CALayer 不是线程安全的,并且只能在主线程创建、访问和销毁。
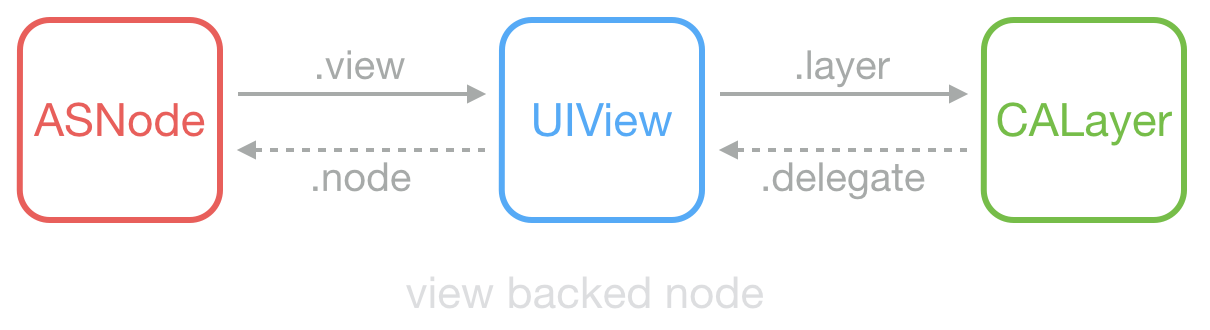
ASDK 为此创建了 ASDisplayNode 类,包装了常见的视图属性(比如 frame/bounds/alpha/transform/backgroundColor/superNode/subNodes 等),然后它用 UIView->CALayer 相同的方式,实现了 ASNode->UIView 这样一个关系。
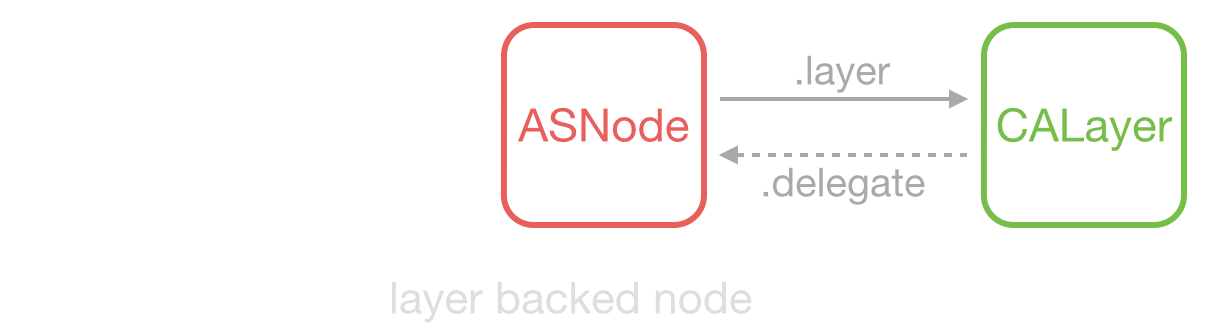
当不需要响应触摸事件时,ASDisplayNode 可以被设置为 layer backed,即 ASDisplayNode 充当了原来 UIView 的功能,节省了更多资源。
与 UIView 和 CALayer 不同,ASDisplayNode 是线程安全的,它可以在后台线程创建和修改。Node 刚创建时,并不会在内部新建 UIView 和 CALayer,直到第一次在主线程访问 view 或 layer 属性时,它才会在内部生成对应的对象。当它的属性(比如frame/transform)改变后,它并不会立刻同步到其持有的 view 或 layer 去,而是把被改变的属性保存到内部的一个中间变量,稍后在需要时,再通过某个机制一次性设置到内部的 view 或 layer。
通过模拟和封装 UIView/CALayer,开发者可以把代码中的 UIView 替换为 ASNode,很大的降低了开发和学习成本,同时能获得 ASDK 底层大量的性能优化。为了方便使用, ASDK 把大量常用控件都封装成了 ASNode 的子类,比如 Button、Control、Cell、Image、ImageView、Text、TableView、CollectionView 等。利用这些控件,开发者可以尽量避免直接使用 UIKit 相关控件,以获得更完整的性能提升。
ASDK 的图层预合成


有时一个 layer 会包含很多 sub-layer,而这些 sub-layer 并不需要响应触摸事件,也不需要进行动画和位置调整。ASDK 为此实现了一个被称为 pre-composing 的技术,可以把这些 sub-layer 合成渲染为一张图片。开发时,ASNode 已经替代了 UIView 和 CALayer;直接使用各种 Node 控件并设置为 layer backed 后,ASNode 甚至可以通过预合成来避免创建内部的 UIView 和 CALayer。
通过这种方式,把一个大的层级,通过一个大的绘制方法绘制到一张图上,性能会获得很大提升。CPU 避免了创建 UIKit 对象的资源消耗,GPU 避免了多张 texture 合成和渲染的消耗,更少的 bitmap 也意味着更少的内存占用。
ASDK 异步并发操作

自 iPhone 4S 起,iDevice 已经都是双核 CPU 了,现在的 iPad 甚至已经更新到 3 核了。充分利用多核的优势、并发执行任务对保持界面流畅有很大作用。ASDK 把布局计算、文本排版、图片/文本/图形渲染等操作都封装成较小的任务,并利用 GCD 异步并发执行。如果开发者使用了 ASNode 相关的控件,那么这些并发操作会自动在后台进行,无需进行过多配置。
Runloop 任务分发
Runloop work distribution 是 ASDK 比较核心的一个技术,ASDK 的介绍视频和文档中都没有详细展开介绍,所以这里我会多做一些分析。如果你对 Runloop 还不太了解,可以看一下我之前的文章 深入理解RunLoop,里面对 ASDK 也有所提及。
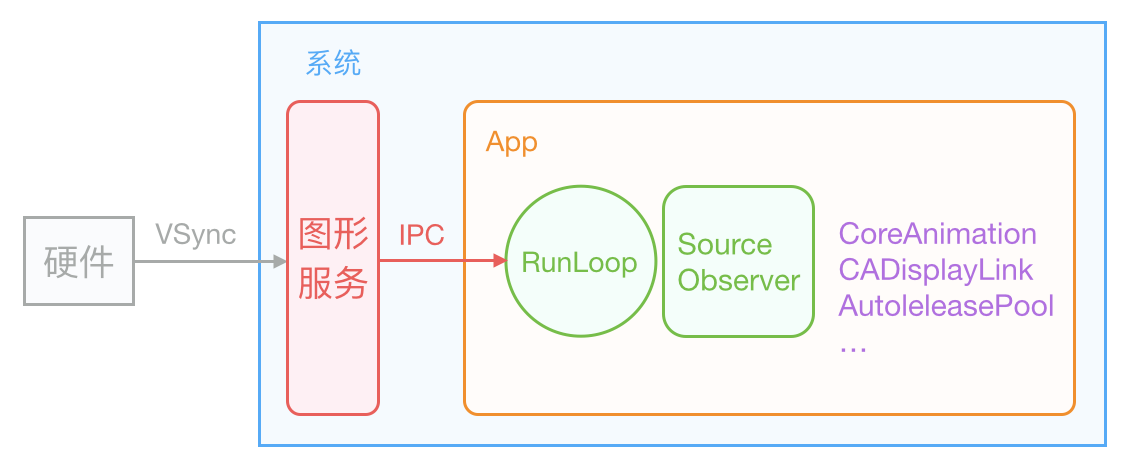
iOS 的显示系统是由 VSync 信号驱动的,VSync 信号由硬件时钟生成,每秒钟发出 60 次(这个值取决设备硬件,比如 iPhone 真机上通常是 59.97)。iOS 图形服务接收到 VSync 信号后,会通过 IPC 通知到 App 内。App 的 Runloop 在启动后会注册对应的 CFRunLoopSource 通过 mach_port 接收传过来的时钟信号通知,随后 Source 的回调会驱动整个 App 的动画与显示。
Core Animation 在 RunLoop 中注册了一个 Observer,监听了 BeforeWaiting 和 Exit 事件。这个 Observer 的优先级是 2000000,低于常见的其他 Observer。当一个触摸事件到来时,RunLoop 被唤醒,App 中的代码会执行一些操作,比如创建和调整视图层级、设置 UIView 的 frame、修改 CALayer 的透明度、为视图添加一个动画;这些操作最终都会被 CALayer 捕获,并通过 CATransaction 提交到一个中间状态去(CATransaction 的文档略有提到这些内容,但并不完整)。当上面所有操作结束后,RunLoop 即将进入休眠(或者退出)时,关注该事件的 Observer 都会得到通知。这时 CA 注册的那个 Observer 就会在回调中,把所有的中间状态合并提交到 GPU 去显示;如果此处有动画,CA 会通过 DisplayLink 等机制多次触发相关流程。
ASDK 在此处模拟了 Core Animation 的这个机制:所有针对 ASNode 的修改和提交,总有些任务是必需放入主线程执行的。当出现这种任务时,ASNode 会把任务用 ASAsyncTransaction(Group) 封装并提交到一个全局的容器去。ASDK 也在 RunLoop 中注册了一个 Observer,监视的事件和 CA 一样,但优先级比 CA 要低。当 RunLoop 进入休眠前、CA 处理完事件后,ASDK 就会执行该 loop 内提交的所有任务。具体代码见这个文件:ASAsyncTransactionGroup。
通过这种机制,ASDK 可以在合适的机会把异步、并发的操作同步到主线程去,并且能获得不错的性能。
其他
ASDK 中还有封装很多高级的功能,比如滑动列表的预加载、V2.0添加的新的布局模式等。ASDK 是一个很庞大的库,它本身并不推荐你把整个 App 全部都改为 ASDK 驱动,把最需要提升交互性能的地方用 ASDK 进行优化就足够了。
微博 Demo 性能优化技巧
我为了演示 YYKit 的功能,实现了微博和 Twitter 的 Demo,并为它们做了不少性能优化,下面就是优化时用到的一些技巧。
预排版
当获取到 API JSON 数据后,我会把每条 Cell 需要的数据都在后台线程计算并封装为一个布局对象 CellLayout。CellLayout 包含所有文本的 CoreText 排版结果、Cell 内部每个控件的高度、Cell 的整体高度。每个 CellLayout 的内存占用并不多,所以当生成后,可以全部缓存到内存,以供稍后使用。这样,TableView 在请求各个高度函数时,不会消耗任何多余计算量;当把 CellLayout 设置到 Cell 内部时,Cell 内部也不用再计算布局了。
对于通常的 TableView 来说,提前在后台计算好布局结果是非常重要的一个性能优化点。为了达到最高性能,你可能需要牺牲一些开发速度,不要用 Autolayout 等技术,少用 UILabel 等文本控件。但如果你对性能的要求并不那么高,可以尝试用 TableView 的预估高度的功能,并把每个 Cell 高度缓存下来。这里有个来自百度知道团队的开源项目可以很方便的帮你实现这一点:FDTemplateLayoutCell。
预渲染
微博的头像在某次改版中换成了圆形,所以我也跟进了一下。当头像下载下来后,我会在后台线程将头像预先渲染为圆形并单独保存到一个 ImageCache 中去。
对于 TableView 来说,Cell 内容的离屏渲染会带来较大的 GPU 消耗。在 Twitter Demo 中,我为了图省事儿用到了不少 layer 的圆角属性,你可以在低性能的设备(比如 iPad 3)上快速滑动一下这个列表,能感受到虽然列表并没有较大的卡顿,但是整体的平均帧数降了下来。用 Instument 查看时能够看到 GPU 已经满负荷运转,而 CPU 却比较清闲。为了避免离屏渲染,你应当尽量避免使用 layer 的 border、corner、shadow、mask 等技术,而尽量在后台线程预先绘制好对应内容。
异步绘制
我只在显示文本的控件上用到了异步绘制的功能,但效果很不错。我参考 ASDK 的原理,实现了一个简单的异步绘制控件。这块代码我单独提取出来,放到了这里:YYAsyncLayer。YYAsyncLayer 是 CALayer 的子类,当它需要显示内容(比如调用了 [layer setNeedDisplay])时,它会向 delegate,也就是 UIView 请求一个异步绘制的任务。在异步绘制时,Layer 会传递一个 BOOL(^isCancelled)() 这样的 block,绘制代码可以随时调用该 block 判断绘制任务是否已经被取消。
当 TableView 快速滑动时,会有大量异步绘制任务提交到后台线程去执行。但是有时滑动速度过快时,绘制任务还没有完成就可能已经被取消了。如果这时仍然继续绘制,就会造成大量的 CPU 资源浪费,甚至阻塞线程并造成后续的绘制任务迟迟无法完成。我的做法是尽量快速、提前判断当前绘制任务是否已经被取消;在绘制每一行文本前,我都会调用 isCancelled() 来进行判断,保证被取消的任务能及时退出,不至于影响后续操作。
目前有些第三方微博客户端(比如 VVebo、墨客等),使用了一种方式来避免高速滑动时 Cell 的绘制过程,相关实现见这个项目:VVeboTableViewDemo。它的原理是,当滑动时,松开手指后,立刻计算出滑动停止时 Cell 的位置,并预先绘制那个位置附近的几个 Cell,而忽略当前滑动中的 Cell。这个方法比较有技巧性,并且对于滑动性能来说提升也很大,唯一的缺点就是快速滑动中会出现大量空白内容。如果你不想实现比较麻烦的异步绘制但又想保证滑动的流畅性,这个技巧是个不错的选择。
全局并发控制
当我用 concurrent queue 来执行大量绘制任务时,偶尔会遇到这种问题:
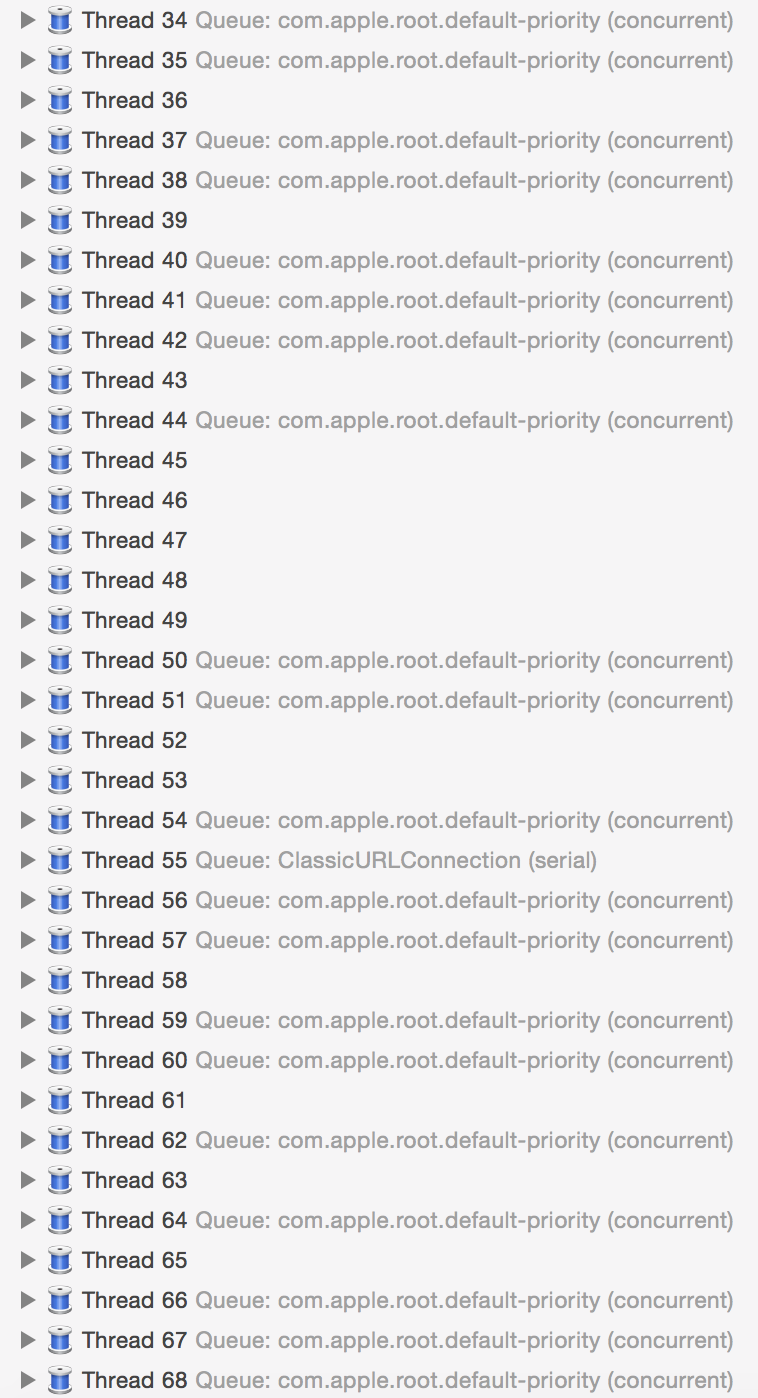
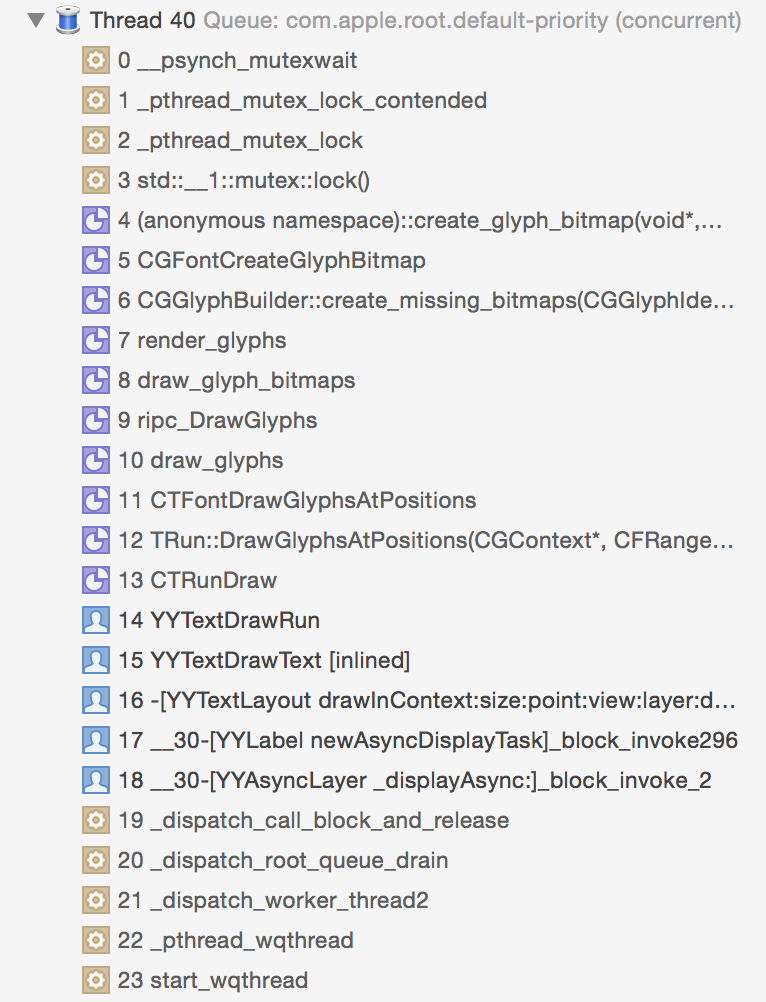
大量的任务提交到后台队列时,某些任务会因为某些原因(此处是 CGFont 锁)被锁住导致线程休眠,或者被阻塞,concurrent queue 随后会创建新的线程来执行其他任务。当这种情况变多时,或者 App 中使用了大量 concurrent queue 来执行较多任务时,App 在同一时刻就会存在几十个线程同时运行、创建、销毁。CPU 是用时间片轮转来实现线程并发的,尽管 concurrent queue 能控制线程的优先级,但当大量线程同时创建运行销毁时,这些操作仍然会挤占掉主线程的 CPU 资源。ASDK 有个 Feed 列表的 Demo:SocialAppLayout,当列表内 Cell 过多,并且非常快速的滑动时,界面仍然会出现少量卡顿,我谨慎的猜测可能与这个问题有关。
使用 concurrent queue 时不可避免会遇到这种问题,但使用 serial queue 又不能充分利用多核 CPU 的资源。我写了一个简单的工具 YYDispatchQueuePool,为不同优先级创建和 CPU 数量相同的 serial queue,每次从 pool 中获取 queue 时,会轮询返回其中一个 queue。我把 App 内所有异步操作,包括图像解码、对象释放、异步绘制等,都按优先级不同放入了全局的 serial queue 中执行,这样尽量避免了过多线程导致的性能问题。
更高效的异步图片加载
SDWebImage 在这个 Demo 里仍然会产生少量性能问题,并且有些地方不能满足我的需求,所以我自己实现了一个性能更高的图片加载库。在显示简单的单张图片时,利用 UIView.layer.contents 就足够了,没必要使用 UIImageView 带来额外的资源消耗,为此我在 CALayer 上添加了 setImageWithURL 等方法。除此之外,我还把图片解码等操作通过 YYDispatchQueuePool 进行管理,控制了 App 总线程数量。
其他可以改进的地方
上面这些优化做完后,微博 Demo 已经非常流畅了,但在我的设想中,仍然有一些进一步优化的技巧,但限于时间和精力我并没有实现,下面简单列一下:
列表中有不少视觉元素并不需要触摸事件,这些元素可以用 ASDK 的图层合成技术预先绘制为一张图。
再进一步减少每个 Cell 内图层的数量,用 CALayer 替换掉 UIView。
目前每个 Cell 的类型都是相同的,但显示的内容却各部一样,比如有的 Cell 有图片,有的 Cell 里是卡片。把 Cell 按类型划分,进一步减少 Cell 内不必要的视图对象和操作,应该能有一些效果。
把需要放到主线程执行的任务划分为足够小的块,并通过 Runloop 来进行调度,在每个 Loop 里判断下一次 VSync 的时间,并在下次 VSync 到来前,把当前未执行完的任务延迟到下一个机会去。这个只是我的一个设想,并不一定能实现或起作用。
如何评测界面的流畅度
最后还是要提一下,“过早的优化是万恶之源”,在需求未定,性能问题不明显时,没必要尝试做优化,而要尽量正确的实现功能。做性能优化时,也最好是走修改代码 -> Profile -> 修改代码这样一个流程,优先解决最值得优化的地方。
如果你需要一个明确的 FPS 指示器,可以尝试一下 KMCGeigerCounter。对于 CPU 的卡顿,它可以通过内置的 CADisplayLink 检测出来;对于 GPU 带来的卡顿,它用了一个 1×1 的 SKView 来进行监视。这个项目有两个小问题:SKView 虽然能监视到 GPU 的卡顿,但引入 SKView 本身就会对 CPU/GPU 带来额外的一点的资源消耗;这个项目在 iOS 9 下有一些兼容问题,需要稍作调整。
我自己也写了个简单的 FPS 指示器:FPSLabel 只有几十行代码,仅用到了 CADisplayLink 来监视 CPU 的卡顿问题。虽然不如上面这个工具完善,但日常使用没有太大问题。
最后,用 Instuments 的 GPU Driver 预设,能够实时查看到 CPU 和 GPU 的资源消耗。在这个预设内,你能查看到几乎所有与显示有关的数据,比如 Texture 数量、CA 提交的频率、GPU 消耗等,在定位界面卡顿的问题时,这是最好的工具。
太凶残~
楼主牛爆了 。。 :idea: :idea:
技术太烂了,看了两遍还有好多没懂。。
真 · 大神
显示器会发出一个水平同步信号(horizonal synchronization),简称 VSync;
应该是HSync :!:
哦哈~改一下 ;-)
Runloop 任务分发这一节不明白,求博主指教一下。第一段说应用界面的显示是由VSync来驱动的,第二段有说Core Animation会在runloop里面注册Observer,在睡眠之前去遍历需要更新的界面。这里是不是有点矛盾,界面更新是在Vsync触发的回调里面进行,还是在runloop进入休眠之前进行,抑或是在这两个时间点都会进行呢
英文不太好,其实干脆就说行场相位更加好理解点.
原理讲解的非常清晰,易懂。
楼主的知识储备是如何建立起来的,能分享下学习方法或者时间安排吗?
原理讲解的非常清晰,易懂。
楼主的知识储备是如何建立起来的,能分享下学习方法或者时间安排吗?
同想知道楼主的知识储备如何建立起来的,求分享心得啊 +1
就是天天在网上逛啊逛的,哪有什么学习方法啊。。 :?:
楼主确实讲的很完善,作为一个app开发者,由下到上都摸到电子上不容易,可以分享下学习经历也可以。
一般都在哪里逛啊?
同问楼主的学习方法,这么完整的一套真的很厉害。不知博主是在哪里看到这些知识的? :roll: :roll:
在不知道谁的微博上,看到说把你忽悠到滴滴。直到现在才看到你写的文章,妈蛋,大半年过去了。这么好的文章,需要这么长时间才看到,?。
楼主我有个疑问 文中有写取得json数据后在后台线程计算并生成一个celllayout对象 假使我创建celllayout后立刻将其传给cell进行布局 那么我无法判断celllayout其中的布局是否计算完成 会不会有celllayout中个别属性为空的现象呢
我这里是使用直接在Cell中写的Layout方法后将其Layout传输到缓存列表中~然后赋值给cell,至于异步layout是不是能保证值有效,在cell中同时增加一个回调和判断呗,渲染完成自动回传layout给model~不知道对不对~
你好,我最近也在研究这个问题,能分享一下你的代码吗,万分感谢!
前排围观
请问博文中的图是用什么软件画的?谢谢
都是 Keynote 画的。
评论 ;-) 开来楼主真的很会“格物”啊,佩服。
:roll: :roll: 评论
;-) 学到很多,看楼主代码中
好屌,佩服!!!
想问一下,博主写这篇文章参考了哪些资料? 能列出来一下吗?
关于屏幕刷新这部分知识能列出参考资料就好了。。
卡顿产生的原因和解决方案
卡顿产生的原因和解决方案
这里似乎没有讲双缓存的作用。
双缓存在 iOS 开发中基本接触不到,所以也没细讲。在网上拿关键词 双缓存、VSync、HSync、垂直同步 等关键词一搜,资料大片大片的~
Woa~写得非常好,实在是佩服,向你学习!
:shock: 震惊。。学习,慢慢消化。。
卧槽,竟然没有占到大神的沙发
评论 :shock: :shock: :shock: :shock: :shock: :shock: :shock: 长知识
这里有个来自百度知道团队的开源项目可以很方便的帮你实现这一点:FDTemplateLayoutCell。
外链地址最后少了一个”l”
https://github.com/forkingdog/UITableView-FDTemplateLayoutCell
另文字很不错,谢谢。 :lol:
已修改~~~
把 Cell 按类型划分,进一步减少 Cell 内不必要的视图对象和操作,应该能有一些效果。
指的是根据不同类型调用不同CELL?那不是多了一份内存吗?
很多优化本来就是空间换时间。。
“随后视频控制器会按照 VSync 信号逐行读取帧缓冲区的数据,经过可能的数模转换传递给显示器显示”,HSync不是逐行吗?这个是逐帧吧,大胆猜测的不知道对不对。。 :cool:
VSync 信号到来后,开始读取,读取时是按照 HSync 指示逐行读取的,这样写会清晰些 ;-)
,你写的库看不懂啊…收我做徒弟吧
还没看完,但是觉得很不错,周末详细阅读以下,非常受用。感谢lz的分享。
view的隐藏可以设置hidden或者设置frame为zero,这2种方式性能 博主有研究过吗?如果性能没区别,微博的多图显示,里面的if、else、switch、case判断太多了,在layout里面计算多图的frame,不够9张的直接把frame设置为zero,里面不需要各种switch判断,然后在cell里面显示也不需要if else判断了
没有实际测试过,不过我觉得 hidden 性能也许会好一些。不过这两种方法实际带来的性能损耗都微乎其微吧。。
设置zero应该会有小点点的那种情况。
Mark,学习了
:o 非常感谢!!!学习到很多!
大爱博主么么哒,混个脸熟,膜拜大神 :razz:
文章和 Framework 都很赞!
:roll: :roll: :roll: 大爱啊,博主棒棒哒!!~~
非常感谢楼主的无私奉献,好东西果断收藏! :idea:
顺便问一下,博主YYKit中图片编解码这一部分的参考资料哪找的? :smile:
楼主的技术,知识广度和深度真是惊为天人!
真心希望楼主能分享一下学习心得。
作为一个iOS菜鸟,梦想有一天变成楼主一半那么牛就可以了哈。
另外,楼主能否分享一些关于iOS app架构方面的心得?app稍微复杂点,view controller就要快爆了。多谢先!
MVC模式能解决你的问题,如果还不能MVVC是候选项
作为ios开发,这文必须点赞
讲的很深入,做了1年半iOS了,看了这篇文章觉得应该反思了,很惭愧
膜拜
:!: 博主,你屏幕截图右下角显示实时FPS的是什么库啊?
评论 :| :| :| :| :|
“对于 TableView 来说,Cell 内容的离屏渲染会带来较大的 GPU 消耗。在 Twitter Demo 中,我为了图省事儿用到了不少 layer 的圆角属性,你可以在低性能的设备(比如 iPad 3)上快速滑动一下这个列表,能感受到虽然列表并没有较大的卡顿,但是整体的平均帧数降了下来。用 Instument 查看时能够看到 GPU 已经满负荷运转,而 CPU 却比较清闲。为了避免离屏渲染,你应当尽量避免使用 layer 的 border、corner、shadow、mask 等技术,而尽量在后台线程预先绘制好对应内容。”
这里是不是写反了,离屏渲染是CPU在做,这里应该是CPU bound, 也就是CPU满负荷,GPU空转
这个你可以测一下看看。。GPU 是满的。。离屏渲染可能在 CPU 也可能在 GPU 里。。
膜拜中,虽然没做IOS,但是也学习到画面卡顿的原因!长知识了!
之前做Android的,现在转做iOS了,希望博主分享更多精彩的文章 :roll:
进来膜拜一下大神
评论 :smile: 赞楼主,很好的分享
博主的评论用的是哪个第三方提供的服务吗?
就是 WordPress 自带的。
YYKIT和Masonry不兼容啊
UIView+YYAdd 里面有未加前缀的方法导致的冲突,具体原因在项目的 readme 里说明了。
博主的知识广度和深度真的让人不得不竖起大拇指,向博主致敬!
认真学习你的文章。有空多教教。
文章写的很全面,学习了。
怒赞赞赞赞赞赞赞赞赞赞赞赞赞赞赞!!
看了下博主的YYKit,感觉太牛了,不知道楼主是怎么学习的,能分享下iOS学习的过程吗?这思路完全不是看个API文档能比的 :roll: YYKit是国人的骄傲啊。更加难得是博主的Git注释有中文讲解,太贴心了~~~~120个星~~
要是代码也有中文注释就好了 :roll: :roll: :roll: :roll:
[大量的任务提交到后台队列时,某些任务会因为某些原因(此处是 CGFont 锁)被锁住导致线程休眠,或者被阻塞,]
什么原因会导致休眠或者被阻塞,项目中刚好碰到了一模一样的问题。
大神可以考虑用AsyncDisplayKit搞个聊天组件Kit的!!!
请教博主一个问题,如果我从服务器获取的图片都是大图,没有做过处理,然后我将他们放入到cell里,拖动的时候会有那么一点点顿卡,我在优化的时候是不是应该先将图片的质量压缩一下在放入到cell里面,这样会好一点
并不会
同样让 CPU 带来了新的挑战
厉害!学习了,赞
收获很大,好样的 :grin:
相见很晚啊
评论 :oops: 谢谢博主的分享,仔细拜读了博主的代码,受益匪浅,期待更多好文 :shock:
亲,你的博客输不出rss了?
人比人气死人,博主你为何这么强大。 :cry: :cry: :cry: :cry:
受益匪浅,特此一赞
KMCGeigerCounter在iOS9的适配,我的做法是延迟一秒启动这个window。请问楼主有没有更优雅的办法?
可以给新建的那个 UIWindow 添加个空的 rootViewController。
唉,话说新建 UIWindow 时会可能会有不少坑。。
简单加个controller,状态栏不见了。。。
这么搞兼容性更好些:https://github.com/ibireme/YYText/blob/master/YYText/Component/YYTextEffectWindow.m#L40-L53
好厉害!学习了!花了不少时间读完文章,了解到很多知识,谢谢!
没看明白 AsyncDisplayKit 和 YYAsyncLayer 的关系
太凶残~
叹为观止~
Runloop 任务分发这一节不明白,求博主指教一下。第一段说应用界面的显示是由VSync来驱动的,第二段有说Core Animation会在runloop里面注册Observer,在睡眠之前去遍历需要更新的界面。这里是不是有点矛盾,界面更新是在Vsync触发的回调里面进行,还是在runloop进入休眠之前进行,抑或是在这两个时间点都会进行呢?
大神啊!能帮忙解答我心中的一个疑惑么 ?
一个不规则图形的两种实现方式:1、drawRect里 CG…. ,2、CAShaperLayer结合UIBerizthPath;
这两种方式哪个更好呢 为什么?
还有平时我们实现某个特殊的动画需要通过不停的重绘达到效果,这样会不会很耗性能呢?如果这样的动画可以通过不停的改变shapeLayer.path可以实现,那后者会不会更好些呢?
评论 ;-) 后者,不过你应该自己拿DEMO去测
脏矩形优化一下就好了
大神,看你的代码真的是要很好的功底呢,看了一天你的代码了,但是有一个地方一直困惑着我,求赐教
– (void)setTransformScale:(CGFloat)v {
[self setValue:@(v) forKeyPath:@”transform.scale”];
}
我实在找不到是怎么关联起来的。
嘿嘿,找到了。原来答案在此:https://developer.apple.com/library/ios/documentation/Cocoa/Conceptual/CoreAnimation_guide/Key-ValueCodingExtensions/Key-ValueCodingExtensions.html
看了博主的文章受益匪浅 ;-) ;-) ;-)
评论 ;-) 博主 YYTextAsyncLayer 里面的- (void)_displayAsync:(BOOL)async 方法中
if (size.width < 1 || size.height < 1) {
CGImageRef image = (__bridge_retained CGImageRef)(self.contents);
self.contents = nil;
if (image) {
dispatch_async(YYTextAsyncLayerGetReleaseQueue(), ^{
CFRelease(image);
});
}
if (task.didDisplay) task.didDisplay(self, YES);
return;
}
这段代码能详细解释一下吗,,为什么宽度或高度小于1的情况要释放image呢? 这个1值是有什么说法吗
layer 的宽或高太小时,就没必要绘制了。
另外,当需要更新 contents 时,旧的 contents 肯定是要被释放掉的,这里只是让它在后台线程释放,与宽高等逻辑没关系。
预渲染这一段 instrument 打错 ^_^
同样是90后,可能我比你还大(我90年的),让我看到你对编程的态度,想想我自己挺惭愧的。向你学习吧!
“当 RunLoop 进入休眠前、CA 处理完事件后,ASDK 就会执行该 loop 内提交的所有任务。”,还是不太明白这么做的好处是什么?为什么要在Runloop进入休眠前去处理?
举个例子:当你在一个方法内多次调整一个 UIView 的 frame 时,改变不能立刻同步到 GPU,那样的代价太大。稍后,当 RunLoop 结束时,再把 frame 的最终状态提交到 GPU,这样就能节省很多资源。当然这里还有其他很多因素。
你好,可以转载您的文章吗?我们将会转载在http://www.cheng95.com/news?cid=5,会注明作者和原文出处。望回复,谢谢!
我博客这些文章可以随意转载~
评论 :oops: 膜拜
由这篇文章进入Garan no Dou,然后看了一遍。受 益 匪 浅 。支持 ;-) ;-)
每次看到英文文档都一脑袋包,魔法师能告诉我怎么提升英文阅读水平吗
大神,你的 demo里, 微博 列表 滑动时内存为什么一直涨啊 ?
首先不要看 Xcode 调试时的内存占用,那个目前可能有 bug,推荐用 Instuments 查看内存。另外,滑动列表时会加载图片,图片会放入内存缓存,所以总内存会增加;当收到内存警告或者 App 退到后台时,内存缓存会被释放。
大神,你有群吗?我有一些问题想问你啊
大神,谢谢。受益匪浅。 :roll: :roll:
。。。。。赞
6666~~~ 顺便分享下学习的其他的链接
https://www.objc.io/issues/3-views/moving-pixels-onto-the-screen/ ( 绘制像素到屏幕上 )
https://robots.thoughtbot.com/designing-for-ios-graphics-performance (iOS图形处理和性能 )
https://lobste.rs/s/ckm4uw/a_performance-minded_take_on_ios_design (iOS离屏绘制的性能和机制分析 )
你也够6的 全英的
你好,正在学习你的源码,有个地方不太理解
// Give user a chance to modify the line’s position.
[container.linePositionModifier modifyLines:lines fromText:text inContainer:container];
明明之前已经计算好了line 的position,为啥还要修改呢
作为回报,推荐三本书给博主(如果看过就算啦):
《一课经济学》一本经济学的入门书籍,《经济学通识》和凯文·凯利的《必然》,前两本都是以通俗的方式讲经济学的,了解了解经济学挺好的,最后一本是讲未来趋势的,也可以读一读,都是好书。貌似后两本只能在罗辑思维的公众号里可以买到。
最后博主能否加一下我的QQ呢,方便以后交流或者向你讨教,谢谢!QQ:1145963852
您这是请教问题吗?如果是,太没诚意了,还做广告呢.
最后,谢谢楼主分享.
评论 :质量好高啊,学到了很多东西,只想说声感谢 roll: :roll:
帅哥, 让你的小伙伴给你设计一个Logo吧, 这么优秀的Demo没有Logo, 简直不忍直视。
大神, 你的 twitter列表的 cell的 nameLabel 控件的宽为什么 不算成根据其内容自动算宽高啊, 否则如果名字太长, 右边就被 dateLabel 覆盖了
牛啊 跟楼主相比 感觉自己这几年都酱油了
写得很好吖,学习啦 :smile:
必须点个赞! :smile:
:roll: 学习..
大神,我用 Instuments的 Allocations 看到滑动 微博列表时 , Persistent Bytes 一直涨啊 , 没 划几页, 就超过 100MB 了
图片有缓存的,退到后台会释放掉。
大神,你的 WebP 这个文件里的静态库 我需要加进我的项目么?
博主,再次看你的文章受益匪浅,想想这几年就码字了,没有认真思考过。向你学习,我该反思了。
但 UIKit 和 Core Animation 相关操作必需在主线程进行?这个相关操作是指什么操作?
真是受教了~~~!
大牛们 ,/Users/xxx/Desktop/xxx/xxx/Lib/YYKit/Image/YYWebImageOperation.h:15:9: ‘YYKit/YYImageCache.h’ file not found 手动导入报这样的错误 :cry: :cry:
hello, 如果把计算text size 放到子线程(boundingRectWithSize),那如果有A, B两个label, B的位置根据A的大小来确定,这种情况,是不是要等A的大小计算完成,再执行下一步。 多谢
sorry, 我的意思是,在一个cell内,有很多label的大小都要动态计算,这个时候该如何使用 子线程计算大小。
条理清晰深入浅出,受益匪浅~
YYModel很精彩。但是比较轻量,大神你会考虑加入字典数组转模型数组这些功能么? :roll:
这个现在就有:[NSArray yy_modelArrayWithClass:User.class];
看了你的文章,感觉很棒,我手头上有一个小demo,不知道能否帮我看一下,就在用coredata高频插入数据的时候,cpu会涨,我不知道为什么会涨,所以无从下手去优化,感觉我已经写死的插入频率。https://github.com/gaojinhsu/HighFrequecyCoreDataDemo :arrow: :arrow: :arrow: :arrow:
迄今为止iOS界面渲染看到的最好的文章!
学习了博主 好厉害啊
:grin: 厉害到爆棚….学习ing。
?楼主辛苦,这篇文章正所谓集百家之所长,加以自己的经验总结出来的,受益匪浅。
说道NSSpain和Scott Goodson,做为当时在场的唯一的中国人,我有幸在现场前排听了他的那次关于ASDK的演讲 :smile: ,印象很深刻。iOS开源社区有你们这样的人才贡献好的项目,前途光明 :twisted:
PS. 那次印象深刻的不光是Scott,还有他女朋友,是个大美女 :idea: 。这小子算是事业爱情双丰收了 :smile:
上拉加载 reloaddata 后 会使FPS降得很厉害,怎么解决呢?
应该是你的请求、解析都方能够在主线程了,请确保主线程没有这些耗时、阻塞 UI 的任务。
请问你解决了吗
请问
– boundingRectWithSize:options:context:
跟UIView 的 sizeThatFits:size
哪个效率更高呢? 应该如何评估?
学习了!这样学知识学什么都会学好的!
“我写了一个简单的工具 YYDispatchQueuePool,为不同优先级创建和 CPU 数量相同的 serial queue,每次从 pool 中获取 queue 时,会轮询返回其中一个 queue。”
请问这里为什么要创建与CPU数量相同的serial queue? :|
对 CPU 敏感的逻辑,线程数大于 CPU 数是没有意义的。当然这里实际上做不到线程的 CPU 绑定,这个数字只是一个大概值。
;-) :| :smile: 总感觉与楼主详见恨晚,今年偶然的机会接触到了串哥,叶大等人,又有机会接触到了百度大神,真感觉自己学习不够深入,明年好好弄了
确实很赞,欣赏这种细心做技术的态度~ 另外,CASharpLayer 应该是 CAShapeLayer 哈
厉害 :cool:
你好,有两个问题请教:
1、为什么说CALayer没有属性,都是根据resolveInstanceMethod为对象临时添加方法;
2、http://opensource.apple.com/source/这个源码站里这些文件夹都是什么意思,我想找某个类(比如objc_class)时该怎么找?
谢谢。
你可以手动给 CALayer 加个属性,然后标记为 dynamic,CALayer 会自动帮你实现这个属性。另外也可以用 Instuments 查看一下调用栈。
NSArray *tmp = self.array;
self.array = nil;
dispatch_async(queue, ^{
[tmp class];
});
这代码怎么就可以做到在线程里析构了?
我看懂的部分:
tmp增加了一下self.array所指对象的引用计数、然后self.array设置为nil干掉self.array对那个对象的引用。只剩tmp对其有引用关系、
我拿不准的部分:
在异步block内随便发送一个信号,会增加下rc。然后block作用域结束,在对应queue里面rc减一,但是此时tmp的引用还在啊?最后rc变为0调用是不是还是在tmp所在线程而不是在queue哪个队列的线程?
我觉得有可能出问题的部分:
如果self.array在别的地方还有依赖,那tmp不是唯一的销毁helper。这一套就没用了、
在 ARC 中,对象会在没有强引用时得到释放。这里,对象会被 block 持有,然后在 block 执行完后(即 queue 队列中)得到释放。另外,如果这个对象在其他地方还有强引用,那确实是释放不了的。
Nice!
NSArray *tmp = self.array;
self.array = nil;
dispatch_async(queue, ^{
[tmp class];
});
tmp的释放不是还在主线程啊?还是没解决释放的问题?? :???:
我测试了一下,也不是在后台线程释放的
http://blog.ibireme.com/2015/11/12/smooth_user_interfaces_for_ios/
『目前每个 Cell 的类型都是相同的,但显示的内容却各部一样,比如有的 Cell 有图片,有的 Cell 里是卡片。把 Cell 按类型划分,进一步减少 Cell 内不必要的视图对象和操作,应该能有一些效果。』
各『部』一样
有一个错别字 :twisted:
评论 ;-) 一上来就懵逼了。感觉做深入确实是很能殊途同归的一个事情,赞。
太凶残了!必须点赞啊!博主写得特别好,争取敲一遍代码! :razz:
大神,问一下:上面说到帧缓冲区的双缓存是视频控制器在读取完成第一个缓冲区的一帧之后渲染到屏幕上,渲染完成之后由 显示器或者其他硬件产生一个V-sync信号,帧缓冲区的指针指向第二个缓冲区的起始地址,但是下面 一段又立即改成了 如果显示器只显示了一半 第一个帧缓冲区的内容,这时候 两个缓冲区的内容交换,显示器会出现卡屏的情况。
上面那段描述是我 理解的显示器成像原理,不知道正确不正确,我的第一个问题是:v-Sync信号发出后,到底是指针 指向发生改变 还是 缓冲区的内容发生交换?第二个问题:当原来没有v-Sync信号机制的时候,显示器是如何保证成像 不出现卡屏的情况的呢?
谢谢~
你好,我遇到一个问题,不知道大神能否帮忙解答:
iOS系统在程序静止的状态下(没有任何事件需要处理),它的屏幕是1秒被刷新60次,但runloop在程序静止的状态下,它是进入睡眠的,这个时候屏幕刷新是由哪个线程完成的?60秒刷新一次跟我们点击屏幕控件屏幕刷新是一回事吗?
你添加了针率,runloop怎么会静止呢?
大神,为什么我用在多线程里绘制的文字是模糊的呢
layer的contentScale为默认的1.0,所以会产生模糊
脸评论都一条不拉的看完了,真的感谢博主,感觉国内技术开发的氛围越来越来越好了,多一些博主这样的人就好了。
文章说道的,“少用 UILabel 等文本控件”。不用文本控件,那用什么显示文字呢?
CATextLayer 使用CoreText渲染的,性能很不错的
视图布局怎么缓存啊?
大神厉害,今天才拜读大神的文章,请问对于如果uitableview里面嵌套了一个webview, 就一个,webview加载完后再取web里面的高度来重新刷新整个uitableview这样的卡顿办法,有什么好的解决方案啊
我仿照大神微博demo,写的列表显示,为什么刷新的时候,tableView会闪烁一下呢?能不闪吗?新人小白求解答??
评论 :roll: :roll: YY大神是我学习的榜样啊!!
亲,yykit这个项目我打开报错,可能是什么原因呢,单独打开yytext项目没有问题,YYTextMagnifier.h和YYTextInput.h报错
可以了,大神,只是不明白为什么用模拟器就会报错呢,错在哪里?能否帮忙解释下
博客写得很不错,进来赞一下
把对象捕获到 block 中,然后扔到后台队列去随便发送个消息以避免编译器警告,就可以让对象在后台线程销毁了。 为什么放入block 中,就会立即销毁吗?不明白其中原理,楼主有推荐文章么?
我重载了一下dealloc方法,发现都是在主线程调用的啊,望楼主赐教;
block持有对象,这样对象不会立即销毁,而阻塞当前线程.当block异步抛向后台队列(选择合适的线程执行)中,当block执行完后,队列不再持有block,就会销毁block,block被销毁了他所持有的对象也会被销毁.
这样做的意义就是对象销毁这种影响性能的事延后或者交给空闲的线程执行,从而保存主线程流畅.
我也测试了一下, 如果是NSObject的子类,会在block所在的线程中被销毁, 如果是UIView的子类, dealloc 销毁都会在主线程中。 所以项目中如果是大型的容器类(内部有很多NSObject对象数据),这种方法很好
:grin: 简直没谁了,666
既然界面每秒60帧的刷新跟主线程是没关系的(手机静止状态,帧率也是60fp/s,runloop处于睡眠),那么为什么主线程执行超时任务卡顿,帧率就会下降呢?静止状态下,每秒60次的刷新是由主线程去提交刷新的吗?
显示器的刷新率和 GPU 渲染的帧速率不是一回事。
instrument最后那个单词拼写错了 :》
我是来找茬的…
博主我转载了你的文章,如果有不妥联系我删除http://blog.csdn.net/ggghub/article/details/51922723
关于对象销毁,
dispatch_async(queue, ^{
[tmp class];
});
这段代码的意义在何?
在YYAsyncLayer.m中- (void)_displayAsync:(BOOL)async {}中的dispatch_async(YYAsyncLayerGetDisplayQueue(), ^{}中的开头已经用了if (isCancelled()) { CGColorRelease(backgroundColor); return;}为什么后面还要判断if (isCancelled()),这个可能没有必要。在你的‘Async Display’中测试,即使已经取消了,就不会再走后续的方法。不存在@property (nullable, nonatomic, copy) void (^didDisplay)(CALayer *layer, BOOL finished); finished为NO的情况。(或者是我理解错误了。)
大神,子线程销毁那一块,如果碰上Reachability这个第三方,会出现线程问题。。。crashXD :???:
哇哦,第一遍看的云里雾里的,坚持多看几遍,一直想找到,文本图像屏幕绘制的原理,今天终于看到了,受益匪浅
文中说如果此处有动画,CA 会通过 DisplayLink 等机制多次触发相关流程。但是我发现动画并不会阻塞主线程的执行,我加了断点也没有发现动画执行的线程。核心动画是否用DisplayLink实现?这个地方又应该怎么理解呢? :grin:
鱼于欲语与雨 回复 : 做IOS一年多了, 只记得刚入行的时候 一个在美国思科 工作的大表哥给我了一句劝告:”上班别去混”……..到今天看了老郭 的这篇文章, 才真是深深的意识到了 别去混 这句话的含义……差距真是越来越大….哎….加油.
第二次看文章,看到这个酣畅淋漓啊,多谢大神。
大神,可以转载这篇博客吗?想让更多的人可以看到,,,
你好 没怎么理解
。对于只需要圆角的某些场合,也可以用一张已经绘制好的圆角图片覆盖到原本视图上面来模拟相同的视觉效果。最彻底的解决办法,就是把需要显示的图形在后台线程绘制为图片,避免使用圆角、阴影、遮罩等属性。
Core Graphics 绘制比较好。不会阻塞线程,也不会引发离屏渲染,对内存的消耗也很低。
大神,请教个问题
初始化一个Label,设置属性
_textLabel = [[YYLabel alloc] initWithFrame:CGRectZero];
_textLabel.numberOfLines = 0;
_textLabel.displaysAsynchronously = YES;
_textLabel.textVerticalAlignment = YYTextVerticalAlignmentCenter;
_textLabel.fadeOnAsynchronouslyDisplay = NO;
_textLabel.clearContentsBeforeAsynchronouslyDisplay = NO;
_textLabel.fadeOnHighlight = NO;
_textLabel.layer.contents = nil;
在赋值textLayout后,tableview滑动时label上的文字会出现放大效果,是什么原因啊
博主在自家公司的项目中用到了YYKit吗?是怎么用的?
评论 ;-)
我在开发中,有这样一个情景,在collection的cell中显示一张图片,该图片是一个table的“截图”, 正常滚动时,直接读取图片缓存就可以了。但是首次需要创建这个table以生成图片,而且table很“重”,这势必会卡顿。于是不得已“异步绘制”,但是这带来另一个不可预知,并偶发的问题:App的很多动画失效,包括navigation的push pop,controller的present,但是自己的UIView,animate…等是正常的。不知道你遇到过没有。另外我们有很多其它的图片是用CG绘制的,这些没有问题。
webImage的示例demo拉动后有轻微卡顿是怎么回事
追加:就是播放的gif有轻微卡顿
写完这一套优化是个大工程,我也来自己轮一个
博主,文章过去一年多了不知道您是否还在维护。
最近在读YYText源码异步绘制那部分,有几个问题想问您一下。
我仿照你建了一个UIView子类TestView,CALayer子类TestLayer。我将TestView的layerClass返回TestLayer。并在TestLayer的display方法打断点。
奇怪的是,如果TestView不重写drawRect方法则display方法不会进入断点,反之则可以。但是YYLabel中没有重写drawRect方法的确亦可以走display方法。(我将TestView继承自UILabel就也不用重写drawRect了,我就是想知道为什么这两个方法会相互限制呢。。。这是问题1,同时为啥我重写drawRect方法后TestView设置的背景色就没了呢。。按照网上的说法设置opaque为NO并不好用。。。问题2)
还有一个是您的方法中display下有一句super.contents = super.contents;
这句是在干啥啊。。。。拆测不出来。。。
最后感谢您在百忙之中抽空看了我的问题。
最最后,有一次面试一家公司,最后CTO在面我的时候很自豪的跟我说:YYKit用过没?作者是我大学宿舍上铺(还是下铺忘了。。)。当时我就觉得做技术能做到你这样成为别人吹牛的资本也是屌爆了,服你! :roll: :roll: :roll: :roll:
绘制流程参考https://blog.csdn.net/Mamong/article/details/94839118
厉害!学习中。。。
深入浅出,很赞的分析文,感谢。
“CALayer 内部并没有属性,当调用属性方法时,它内部是通过运行时 resolveInstanceMethod 为对象临时添加一个方法,并把对应属性值保存到内部的一个 Dictionary 里”,这样的话,第一次调用确实比较耗性能,但是之后的调用应该可以直接调用,对性能的影响应该不大了吧?
“为了解决这个问题,GPU 通常有一个机制叫做垂直同步(简写也是 V-Sync),当开启垂直同步后,GPU 会等待显示器的 VSync 信号发出后,才进行新的一帧渲染和缓冲区更新。”
请问一下博主,如果GPU 会等待显示器的 VSync 信号发出后,才进行新的一帧渲染和缓冲区更新的话,那么跟只有一个帧缓冲区还有什么区别?
写入缓冲区1和读取缓冲区2可以同时进行,如果只有一个的话就只能读完了写,写完了再读,多了等待期
分享个不错的存储框架https://github.com/huangzhibiao/BGFMDB
完美支持:
int,long,signed,float,double,NSInteger,CGFloat,BOOL,NSString,NSNumber,NSArray,NSDictionary,NSMapTable,NSHashTable,NSData,UIImage,NSDate,NSURL,NSRange,CGRect,CGSize,CGPoint,自定义对象 等的存储.
每次看你的文章都好像是在读一本小册子 都是先扫一眼收藏下来 找个时间段静下心来慢慢研究
偶像,可以交个朋友吗,隔段时间就会进来复习一波,求加个联系方式… :???:
imageNamed:
立即解码
我现在正在优化tableview的滑动流畅度,看了你这篇文章后,感觉任重道远。。。
“由于垂直同步的机制,如果在一个 VSync 时间内,CPU 或者 GPU 没有完成内容提交,则那一帧就会被丢弃,等待下一次机会再显示,而这时显示屏会保留之前的内容不变。这就是界面卡顿的原因。”
对上面这段话有点疑义,
按照上面的说法,假设因为渲染内容过多,帧率稳定在30fps(2次垂直同步渲染新的一帧),还是会产生卡顿.
但实际上可能不会有卡顿感,因为产生卡顿的原因是帧率的不稳定被人脑识别出来所产生的感觉.前面的假设稳定在30fps,而30fps已经足够流畅了.
目前每个 Cell 的类型都是相同的,但显示的内容却各部一样 有个错别字错误 不 :!:
有个关于微博demo的问题,demo里,在处理数据的时候就穿件不用的WBStatusLayout放到数组里,这里不会有问题吗,楼主用的测试数据创建了7个,当然没问题,如果真是环境下微博数量有几十个,这里岂不是会一下创建几十个layout,要怎么处理呢?
最后谢谢楼主分享的各种知识,赞!
有个关于微博demo的问题,demo里,在处理数据的时候就创建不同的WBStatusLayout放到数组里,这里不会有问题吗,楼主用的测试数据创建了7个,当然没问题,如果真实环境下微博数量有几十个,这里岂不是会一下创建几十个WBStatusLayout视图,要怎么处理呢?
最后谢谢楼主分享的各种知识,赞!
预排版的时候,服务器如果没有给图片的大小,有什么好的办法获取图片的宽高吗?一定要把数据请求下来才可以把?
全局并发控制这里使用NSOpeartionQueue不是可以控制并发数量吗?
请教下楼主,这些都是看英文博客总结的么?想请教下学习方法
感谢楼主分享,大致看完感觉提升了眼界,向楼主学习! :smile:
感觉来晚了
请问一下,如果使用大量CALayer的话,那就必须使用frame进行界面布局了吧?还可以使用Masonry吗?
“由于垂直同步的机制,如果在一个 VSync 时间内,CPU 或者 GPU 没有完成内容提交,则那一帧就会被丢弃,等待下一次机会再显示,而这时显示屏会保留之前的内容不变。这就是界面卡顿的原因。”
对上面这段话有点疑义,
按照上面的说法,假设因为渲染内容过多,帧率稳定在30fps(2次垂直同步渲染新的一帧),还是会产生卡顿.
但实际上可能不会有卡顿感,因为产生卡顿的原因是帧率的不稳定被人脑识别出来所产生的感觉.前面的假设稳定在30fps,而30fps已经足够流畅了.
看了下YYAsyncLayer的源码,对于单层的layer可以理解了,不知道针对多层级的layer能不能正常绘制?
受益匪浅,感谢大神!
兄弟,要小弟吗?
对象销毁不是可以释放资源了吗,怎么还会销毁资源
楼主您好,关于您在文章中讲到的预排版这个技术,我想深入研究一下,有没有使用这个技术的库推荐学习呢?如果有的话麻烦楼主告知,万分感谢!
终于搞懂了PC游戏里面的垂直同步选项是啥意思!
感谢大神,受益匪浅!
“最彻底的解决办法,就是把需要显示的图形在后台线程绘制为图片,避免使用圆角、阴影、遮罩等属性” 这个用什么方法绘制成圆角图片?
差点看懂了
大神,请问一下,YYTextLinePositionModifier这个协议。将每行文本的高度位置固定下来,不受中英文/emoji字体的ascent/dscent影响。这里主要设置了position.y,那怎么保证绘制的文字是在计算到的文本高度内呢(heightforlinecount:方法)。
屏幕上能看到的所有文本内容控件,包括 UIWebView,在底层都是通过 CoreText 排版、绘制为 Bitmap 显示的。常见的文本控件 (UILabel、UITextView 等),其排版和绘制都是在主线程进行的,当显示大量文本时,CPU 的压力会非常大。
应该是GPU压力会非常大?
排版和绘制都是core animation的工作,这部分是CPU处理的,后续才会交给GPU渲染。它这里没讲GPU是否压力大,但是CPU的确是压力大。
为不同优先级创建和 CPU 数量相同的 serial queue,每次从 pool 中获取 queue 时,会轮询返回其中一个 queue。我把 App 内所有异步操作,包括图像解码、对象释放、异步绘制等,都按优先级不同放入了全局的 serial queue 中执行,这样尽量避免了过多线程导致的性能问题
这里能不能通过信号量做呢
都放到串行队列,那不又卡了?信号量是用在多线程的线程安全的,串行不存在多线程同时访问情况。
多线程性能问题,可以限制线程个数即可。
2022年了,读这篇文章依然受益匪浅
作者现在还在开发iOS吗